Key Takeaways
- RPA, AI extraction, and API integrations each reduce manual entry but still leave residual errors that compound across pipeline records and forecasts.
- Agent-based systems like Coffee reach higher accuracy by ingesting email, calendar, and call transcripts directly, which removes human entry entirely.
- The 1-10-100 rule shows CRM data errors rise from $1 to prevent, to $10 to correct, to $100 once propagated, so sub-1% error rates protect EBITA.
- Coffee’s Companion App adds agent-grade accuracy to existing Salesforce or HubSpot instances without migration, while the Standalone CRM fits 1–20 person teams starting fresh.
- Teams ready to eliminate data-entry errors and protect revenue should review Coffee’s pricing and deployment options today.
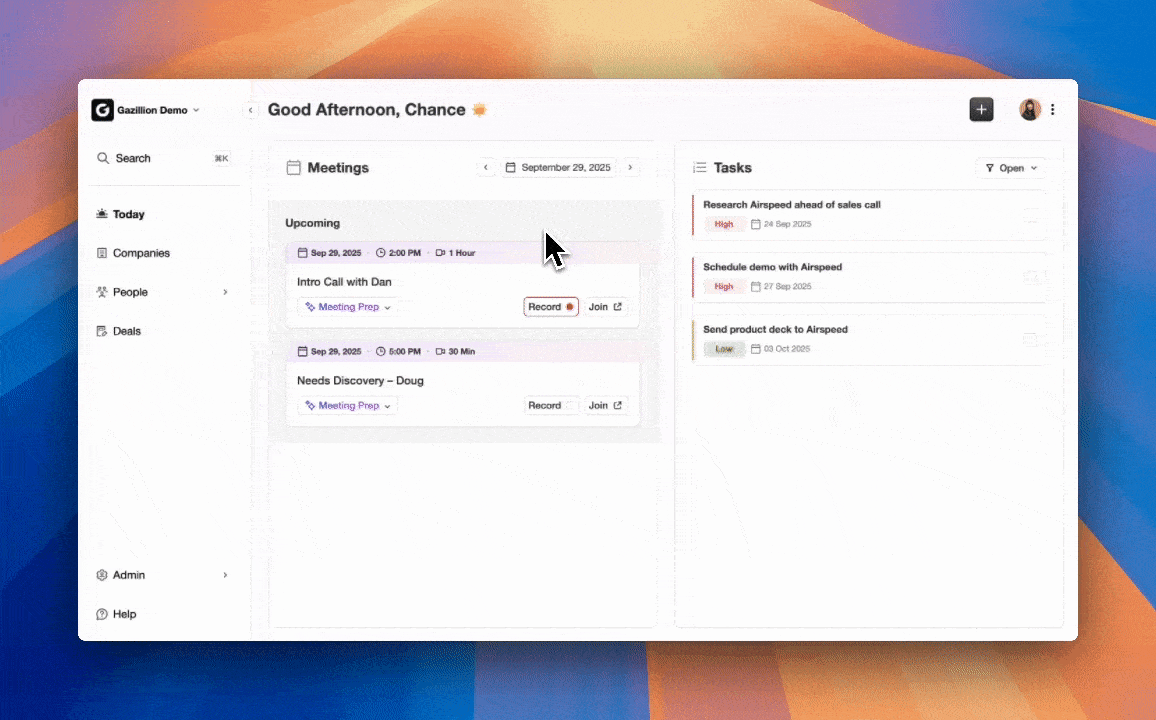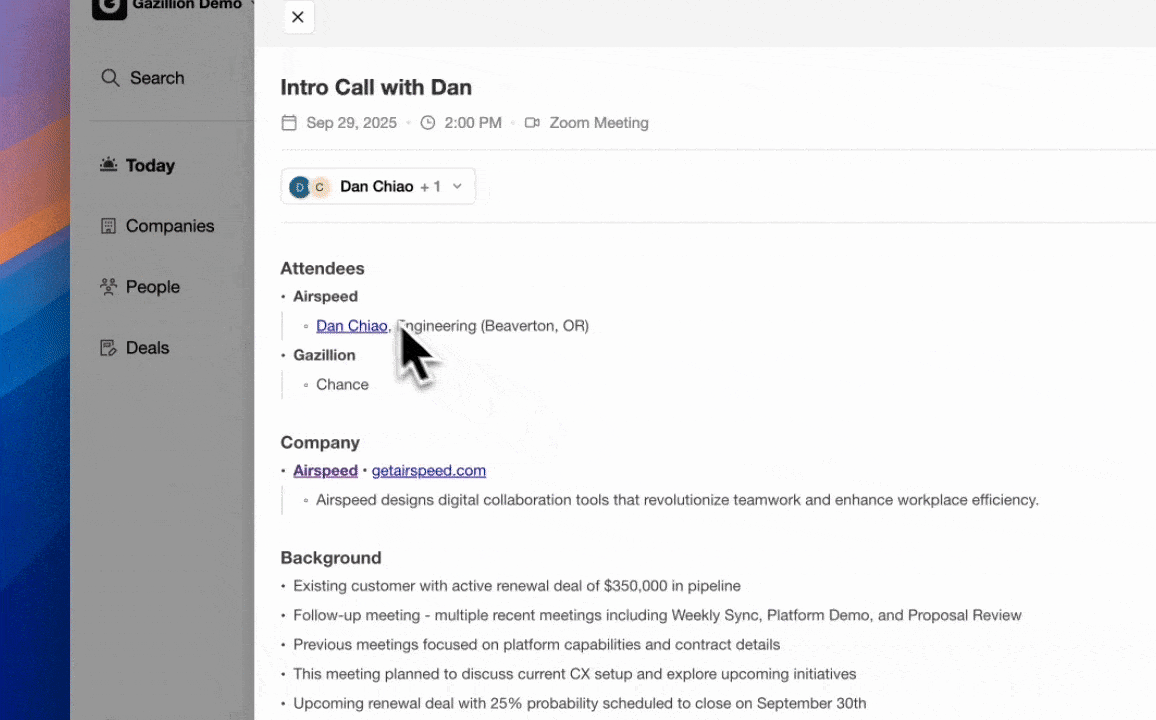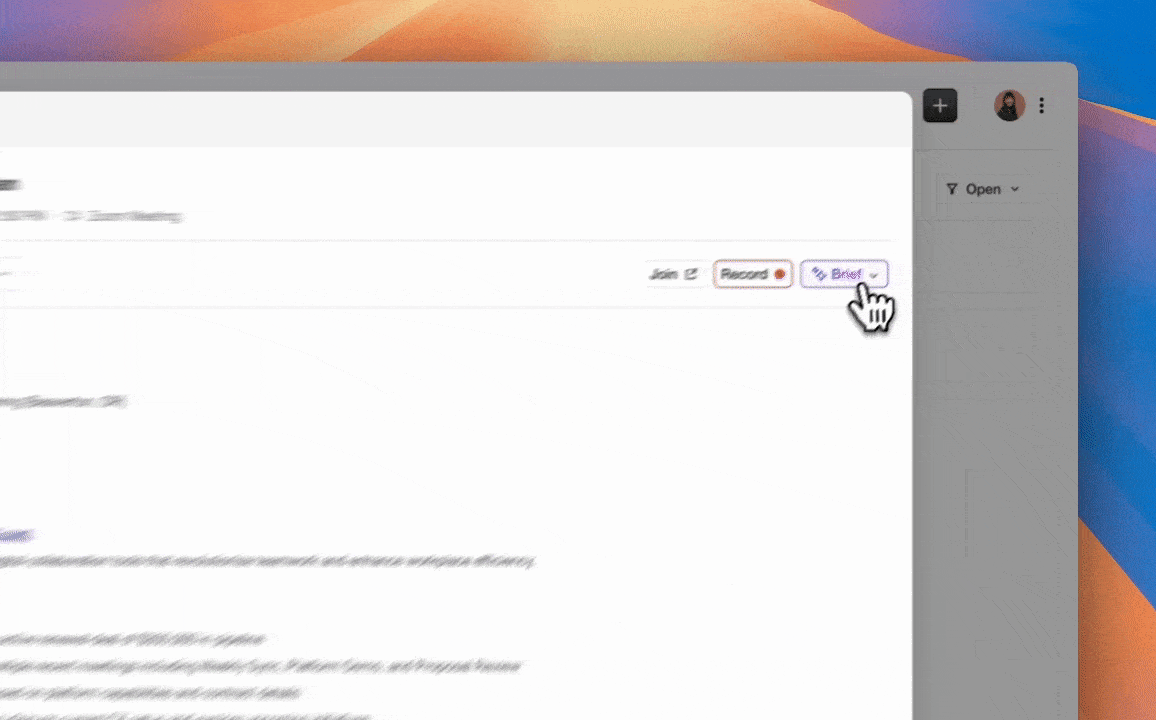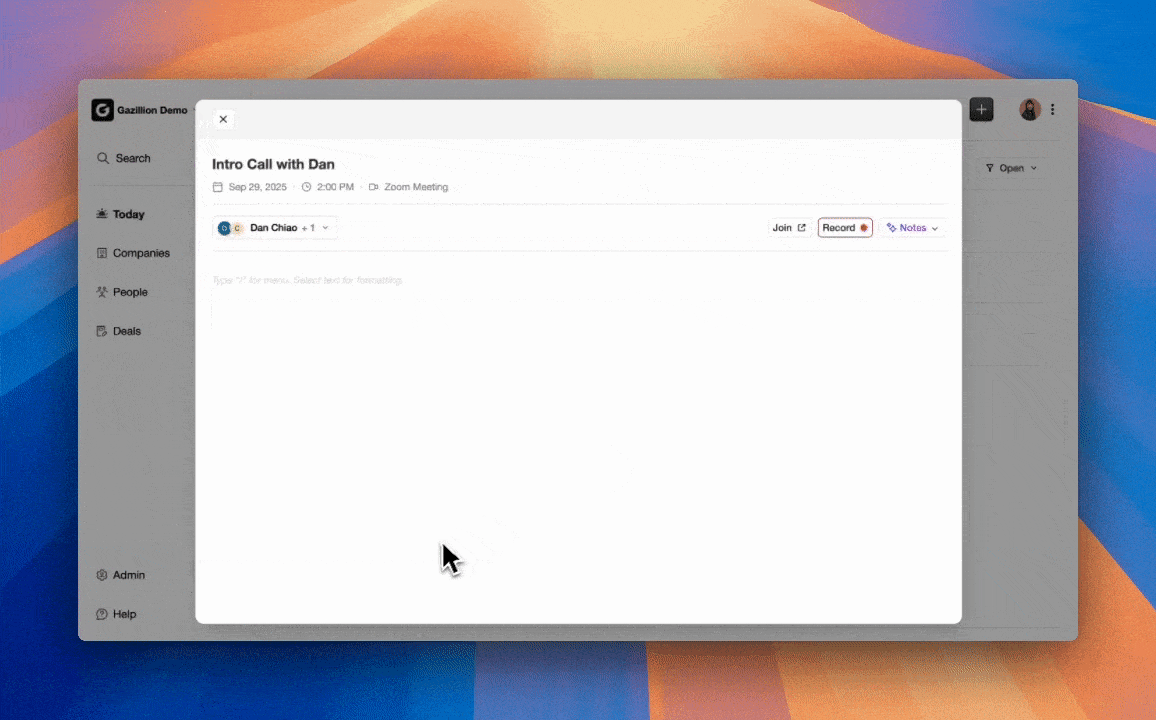
How This Comparison Works and What It Measures
RPA (Robotic Process Automation) uses fixed scripts to move structured data between systems, such as copying a contact from a spreadsheet into a CRM field. AI extraction applies machine learning to parse semi-structured or unstructured inputs such as email bodies or PDF attachments. API integrations sync records between platforms using defined endpoints and achieve high fidelity when schemas align. Agent-based systems combine reasoning, context awareness, and direct data ingestion to create, enrich, and update CRM records without human intervention.
The five evaluation criteria in this comparison are accuracy rate, pipeline error impact, implementation effort, integration depth, and maintenance burden. The table below summarizes how each method performs on accuracy, while the rest of the article explains where those numbers hold up and where they break.
2026 Accuracy Benchmarks Side-by-Side
| Method | 2026 Accuracy Rate | Source |
|---|---|---|
| RPA | Reliable on structured inputs | Zapier, agentic AI vs RPA |
| AI Extraction | High under clean data conditions | Intelligent OCR benchmarks, Terralogic |
| API Integration | High when schemas align | AlphaBold CRM data quality analysis, 2026 |
| Agent-Based (Coffee) | High by eliminating human entry | Coffee direct email/calendar/transcript ingestion |
Human input in traditional data entry can produce errors, while AI-enhanced systems can achieve high accuracy, and Coffee’s agent reaches that benchmark by removing the human from the entry loop entirely.
How Each Method Handles Data Capture and Unstructured Inputs
RPA operates exclusively on structured data. RPA relies on fixed scripts that process structured data only, shows minimal adaptability, and requires rule updates when conditions change. A contact record in a defined CSV column is within scope. A deal update buried in an email thread is not.
AI extraction closes part of that gap. Intelligent OCR systems achieve 95–99% accuracy on unstructured documents including handwritten text, complex tables, and multi-language formats. Accuracy drops when context spans multiple documents or requires reasoning across a conversation thread.
API integrations handle structured fields reliably but cannot parse meaning from unstructured sources. A sync between HubSpot and a dialer platform logs call duration. It does not extract the objection a prospect raised or the next step a rep committed to.
Agent-based systems process both structured and unstructured data. Coffee ingests emails, calendar events, and call transcripts, then turns that content into CRM fields such as contact records, activity logs, deal stage updates, and follow-up tasks without a human intermediary. Agentic AI workflows use dynamic, context-aware reasoning for decision logic, so the agent decides which data matters and where it belongs in the record.
Working With Salesforce and HubSpot Without Replacing Them
HubSpot’s unified data model runs marketing, sales, and service on the same source code, which minimizes cross-system mapping errors and supports higher consistency for automated data entry flows in 2026. HubSpot automatically enriches contact data and logs emails and meetings without manual input, directly removing many human-entry error opportunities, but only for interactions that pass through HubSpot’s native connectors. Emails sent outside the BCC logging workflow or calls recorded in a third-party tool remain invisible.
Salesforce offers deep customization but carries architectural constraints. 76% of CRM users report that less than half of their organization’s CRM data is accurate and complete. That figure holds across platforms when human entry remains part of the process.
Coffee’s Companion App deploys as an intelligent layer on top of existing Salesforce or HubSpot instances. A simple authentication lets the Coffee agent sync data, enrich records, and write insights back to the primary CRM while preserving the system of record. Existing records, workflows, and reporting structures stay intact.
Deploy Coffee’s Companion App on your existing Salesforce or HubSpot instance in minutes.
Scaling Automation Without a Heavy Maintenance Burden
RPA maintenance is continuous. Every time a source application updates its UI or data schema, scripts break. RPA shows minimal adaptability and requires rule updates when conditions change, which creates a permanent engineering dependency that grows with process complexity instead of revenue.
AI extraction models need retraining when document formats shift or new data sources appear. API integrations depend on vendor stability, so a breaking change in a third-party API can silently corrupt records until someone spots a discrepancy in a pipeline review.
Agent-based systems reduce this risk because the agent adapts its reasoning instead of executing a brittle rule set. Coffee’s agent re-plans mid-execution and handles new email formats, new meeting tools, and new team members without manual reconfiguration.
Matching Automation Methods to Company Size and Maturity
Teams of 1–20 people that have outgrown spreadsheets benefit most from Coffee’s Standalone CRM because there is no legacy system to preserve and the agent manages the entire data lifecycle from day one. Once a team reaches 10–50 people and has already committed to Salesforce or HubSpot, Coffee’s Companion App becomes the better fit and adds agent-grade accuracy without forcing a platform migration. As companies grow into mid-market scale with established RevOps functions, the Companion App’s value shifts toward consolidating tooling by replacing separate enrichment tools, call recording platforms, and manual pipeline review exports with a single agent layer.
RPA remains viable for high-volume, highly structured data transfer tasks where inputs never deviate from a fixed schema. API integrations suit scenarios where two platforms share a stable data model and unstructured data capture is not required.
What the 1-10-100 Rule Means for CRM Data Costs
The 1-10-100 rule introduced earlier shows that preventing a data error costs $1, correcting it after entry costs $10, and fixing it after it has propagated through downstream systems costs $100. Applied to CRM data, a 3% error rate across 500 contact records per month generates 15 corrupted records. At $10 per correction, that equals $150 per month in direct remediation. When those errors reach forecasting models, territory assignments, or commission calculations, the $100-per-error tier applies.
Companies lose between 1% and 5% of EBITA annually due to revenue leakage, with fragmented systems contributing significantly to these losses. Even a 2–3% error rate in manual processing becomes material once labor and reprocessing costs are quantified. Cutting error rates from 3% to below 1% through agent-based automation protects EBITA, not just data hygiene.
44% of organizations report losing over 10% in annual revenue due to low-quality CRM data. Many employees spend significant time moving and correcting data. Coffee’s agent removes both the error and the correction labor by capturing ground-truth data at the source.
Eliminate the 1-10-100 cost penalty by exploring Coffee’s pricing and setup options.
Risks of Incomplete Automation for AI-Driven Revenue Teams
The 1-10-100 cost structure assumes errors are eventually caught and corrected. Incomplete automation creates a worse scenario, where errors never surface because the data was never captured at all. 74% of enterprises using CRM reported adopting AI features by Q4 2023, while nearly half (48%) admitted their revenue data was not AI-ready. Partial automation, where some interactions are logged automatically and others depend on rep entry, creates inconsistent records that undermine every downstream AI function, from lead scoring to forecasting.
AI-driven lead scoring can deliver up to 40% higher accuracy than rule-based or manual approaches. Incomplete automation preserves the “garbage in, garbage out” cycle that makes legacy CRMs unreliable. The only exit from that cycle is removing human entry as a dependency rather than simply reducing it.
Decision Framework Checklist for Choosing an Automation Path
Use this checklist to match your current data environment and team structure to the automation method that fits best.
- Data is entirely structured and schema-stable: API integration is sufficient, and RPA is viable but fragile.
- Data includes emails, call transcripts, or meeting notes: AI extraction or agent-based systems are required, because RPA and basic API syncs cannot process unstructured inputs.
- Team size is 1–20 with no existing CRM: Coffee Standalone CRM lets the agent handle the full data lifecycle.
- Team is 10–50+ with Salesforce or HubSpot already deployed: Coffee Companion App adds 99%+ accuracy without a platform migration.
- Forecast accuracy and pipeline reviews are unreliable: Agent-based ingestion is the only method that captures deal context such as objections, next steps, and stage changes from unstructured sources automatically.
- Engineering bandwidth for maintenance is limited: Remove RPA from consideration because agent-based systems adapt without rule rewrites.
- Revenue leakage from bad data is measurable: Sub-1% error rates from agent ingestion are the only benchmark that closes the gap identified by the 1-10-100 rule.
Frequently Asked Questions
What is a realistic accuracy rate for automated CRM data entry in 2026?
Accuracy rates vary by method. RPA achieves reliable accuracy on structured inputs. AI extraction and API integrations can reach high accuracy under clean data conditions. Agent-based systems that ingest email, calendar, and transcript data directly, removing human entry, can reach superior accuracy. The ceiling for any method depends on how much unstructured data it can process and whether a human remains in the entry loop.
How does the 1-10-100 rule apply to CRM data errors specifically?
The 1-10-100 rule quantifies the rising cost of data errors at each stage of propagation. In a CRM, a contact field entered incorrectly costs roughly $1 to prevent at the point of capture. Correcting it after it enters the system costs about $10 in research and reprocessing time. When that error reaches a forecast model, a commission calculation, or a territory assignment, remediation costs approach $100 per instance. At a 3% error rate across hundreds of monthly records, the compounding cost becomes material to EBITA within a single quarter.
Can an agent-based system work alongside an existing Salesforce or HubSpot instance without replacing it?
Yes. Coffee’s Companion App deploys as an agent layer on top of existing Salesforce or HubSpot installations. After a simple authentication, the Coffee agent ingests emails, calendar events, and call transcripts, then writes structured data such as contacts, activity logs, deal updates, and meeting summaries back into the existing CRM. Existing records, custom fields, workflows, and reporting structures remain intact. The agent handles data entry, and the platform of record stays the same.
Why do API integrations still produce data quality problems if they are automated?
API integrations sync structured fields between platforms reliably but cannot capture meaning from unstructured sources. A sync between a dialer and a CRM logs call duration and outcome codes. It does not extract the objection a prospect raised, the next step a rep committed to, or the competitive intelligence surfaced during the call. Those gaps leave the CRM record incomplete. Incomplete records produce inaccurate forecasts, missed follow-ups, and lead scoring errors, regardless of how reliable the API connection is.
What makes agent-based CRM automation different from AI-powered features already built into Salesforce or HubSpot?
Native AI features in Salesforce and HubSpot operate on data that already exists in the platform. They can summarize a record or suggest a next step only when the underlying activity data was logged. When reps skip logging, which happens consistently because 71% of sales reps report spending too much time on data entry, the native AI has nothing to use. Coffee’s agent captures data at the source, before it reaches the CRM, so the record is complete and accurate before any AI feature attempts to use it.
Conclusion: Moving to Trustworthy, Agent-Grade Pipeline Data
RPA, AI extraction, and API integrations each reduce manual entry, but none removes it. Each method leaves a residual error rate that compounds across pipeline records, forecast models, and revenue calculations, and the 1-10-100 rule ensures those errors stay expensive.
Agent-based automation removes human entry as a dependency. By ingesting email, calendar, and transcript data directly, Coffee’s agent captures ground-truth deal context and writes it into the CRM automatically, which delivers high accuracy without adding headcount or replacing existing systems.
Coffee operates in two deployment models: a Standalone CRM for teams building from scratch and a Companion App that adds agent-grade accuracy on top of existing Salesforce or HubSpot instances. Both models deliver the same outcome, which is complete, accurate pipeline data that makes forecasts reliable and rep time productive.