Written by: Doug Camplejohn, CEO & Co-Founder, Coffee
Key Takeaways
- Enterprise CDPs unify behavioral and transactional data into persistent profiles but demand expensive engineering resources for data quality and maintenance.
- Standalone CRMs depend on manual rep entry, which degrades data quality, hurts adoption, and undermines pipeline forecasts.
- Agent-powered hybrids like Coffee automatically capture emails, calendars, and call transcripts, removing manual entry while integrating with existing Salesforce or HubSpot systems.
- Key decision factors include engineering headcount, implementation timeline, compliance needs, and whether teams already invest in Salesforce or HubSpot.
- For teams seeking unified data quality without CDP overhead, see if Coffee’s standalone or companion model fits your constraints.
How Enterprise CDPs and Standalone CRMs Actually Work
CDP.com draws a clear distinction: a CRM stores known customer interactions such as sales calls and support tickets with manually entered data. A CDP automatically ingests behavioral, transactional, and interaction data from every touchpoint and resolves it into unified profiles. The practical gap between those definitions consumes most RevOps budgets. Common triggers for a CDP layer include customer data spread across five or more systems, personalization that relies on manual exports, or a need for AI-driven marketing without a unified data foundation. To navigate these gaps in a repeatable way, teams benefit from a structured evaluation framework.
Evaluation Criteria for CDP vs CRM Decisions
These nine criteria form that framework and help you decide which architecture fits your organization:
- Data quality and maintenance
- Implementation time and cost
- Workflow fit and user adoption
- Integration complexity
- Reporting and pipeline visibility
- Automation depth
- Governance and compliance
- Scalability
- Long-term administrative burden
Side-by-Side Comparison of CDP, CRM, and Agent-Powered Hybrid
The table below compares all three architectures across the nine criteria that shape total cost of ownership and long-term viability. Focus on the “Data quality and maintenance” and “Long-term administrative burden” rows, because these often hide costs that exceed initial license fees.
| Criteria | Enterprise CDP | Standalone CRM | Agent-Powered Hybrid (e.g., Coffee) |
|---|---|---|---|
| Data quality and maintenance | High potential, but requires dedicated data engineering resources for ongoing hygiene | Dependent on manual rep entry, and maintenance burden shifts toward configuration and quality control | Agent auto-captures emails, calendars, and call transcripts, which removes manual entry dependency |
| Implementation time and cost | Often takes several months with significant implementation investment separate from license fees | Typical timelines run 1–3 months for small businesses and 6–12+ months for complex organizations, with lower upfront cost but ongoing admin staffing | Days to weeks through pre-built integrations, with simple authentication for Salesforce or HubSpot companion deployment |
| Workflow fit and user adoption | Serves engineering and data teams, and standalone CDPs require significant upfront implementation before unified data becomes usable | Serves sales reps, yet adoption stays low because of manual entry burden, and adoption depends on workflow fit and governance | Agent handles busywork so reps interact with briefings and summaries instead of data-entry forms |
| Integration complexity | Suite-embedded CDPs often require lengthy implementations and deep ecosystem commitment, while composable stacks typically need a mature data warehouse first | Offer native integrations with common tools, yet fragmented point-solution sprawl appears at scale | Connects through Google Workspace, Microsoft 365, Zoom, and Teams, with Zapier for broader stacks and deep Salesforce or HubSpot sync |
| Reporting and pipeline visibility | Delivers advanced cross-channel analytics but needs data modeling investment before insights appear | Provides pipeline views that depend on rep-entered data quality, so teams often fall back to manual CSV exports | Tracks automated pipeline comparisons and week-over-week deal changes without manual exports |
| Automation depth | Agentic CDPs support autonomous multi-step workflows across CRM and campaign platforms, yet engineering teams must configure them | Delivers rule-based automation, and HubSpot offers fast time-to-value but consumption-based billing creates cost unpredictability at scale | Agent autonomously logs activities, drafts follow-ups, prepares meeting briefings, and builds prospect lists through natural language |
| Governance and compliance | Each reverse ETL sync copies PII to downstream tools, which expands breach-notification obligations, while warehouse-native CDPs improve auditability | Centralizes records with a simpler compliance footprint but limited consent management tooling | Maintains SOC 2 Type 2 and GDPR compliance, and does not use data to train public models |
| Scalability | Composable stack costs rise non-linearly as sync volume, frequency, and destination count increase | Runs at $175–$350 per user each month depending on Salesforce tier, with AI add-ons on top | Uses seat-based pricing where agent labor is included without LLM usage metering |
| Long-term administrative burden | Requires a dedicated team that includes architects, data engineers, a governance lead, and domain stewards | Needs admin headcount for configuration, hygiene, and integration governance, and shadow CRMs appear when adoption fails | Relies on the agent for ongoing data capture, so administrative work centers on agent configuration instead of data entry |
Compare Coffee’s pricing to your current CRM and CDP spend
Category-by-Category Tradeoffs to Expect
Setup and onboarding realities. Composable CDPs can deploy faster when a mature data warehouse already exists. Organizations without that foundation must first invest time building the warehouse layer. Traditional CRM deployments for small businesses typically take 1–3 months, while larger or complex organizations often require 6–12+ months and front-load configuration work that frequently stalls before full adoption.
Data capture and ongoing hygiene. Organizations that implement unified customer profiles can see substantial marketing efficiency gains, with one report citing 67% from eliminating redundant messaging. That unification depends on sustained engineering investment. Standalone CRMs rely on reps who spend up to 30% of their week hunting for information across fragmented systems, which turns forecasts into guesswork.
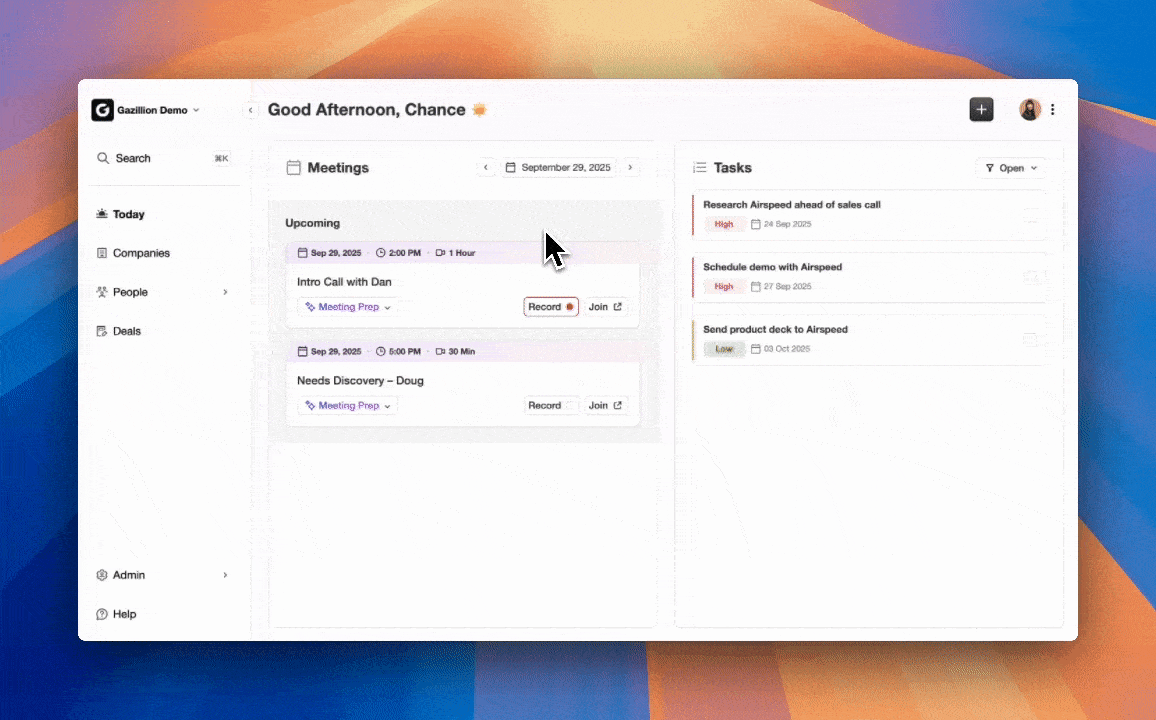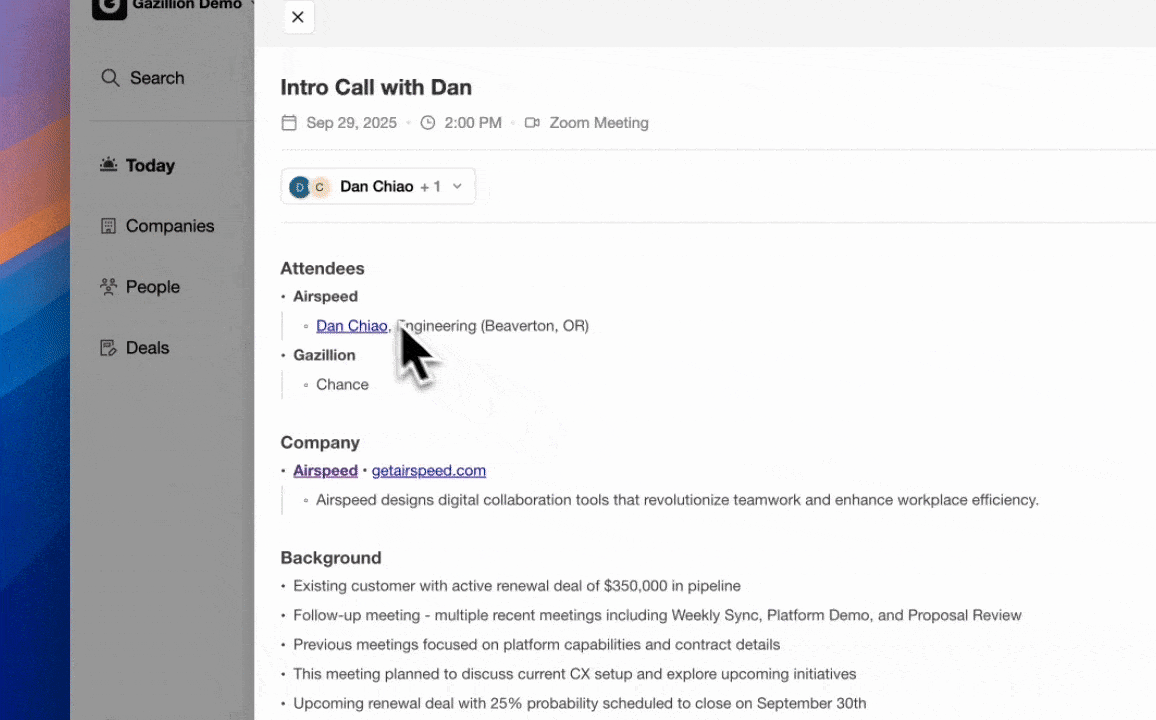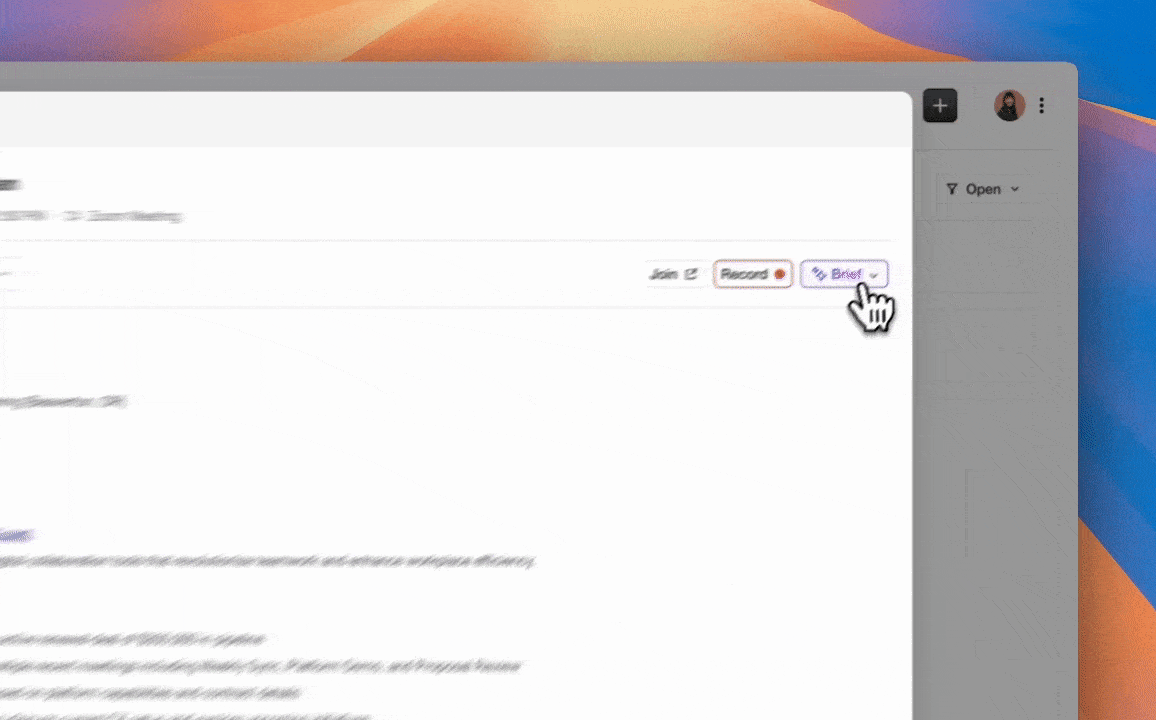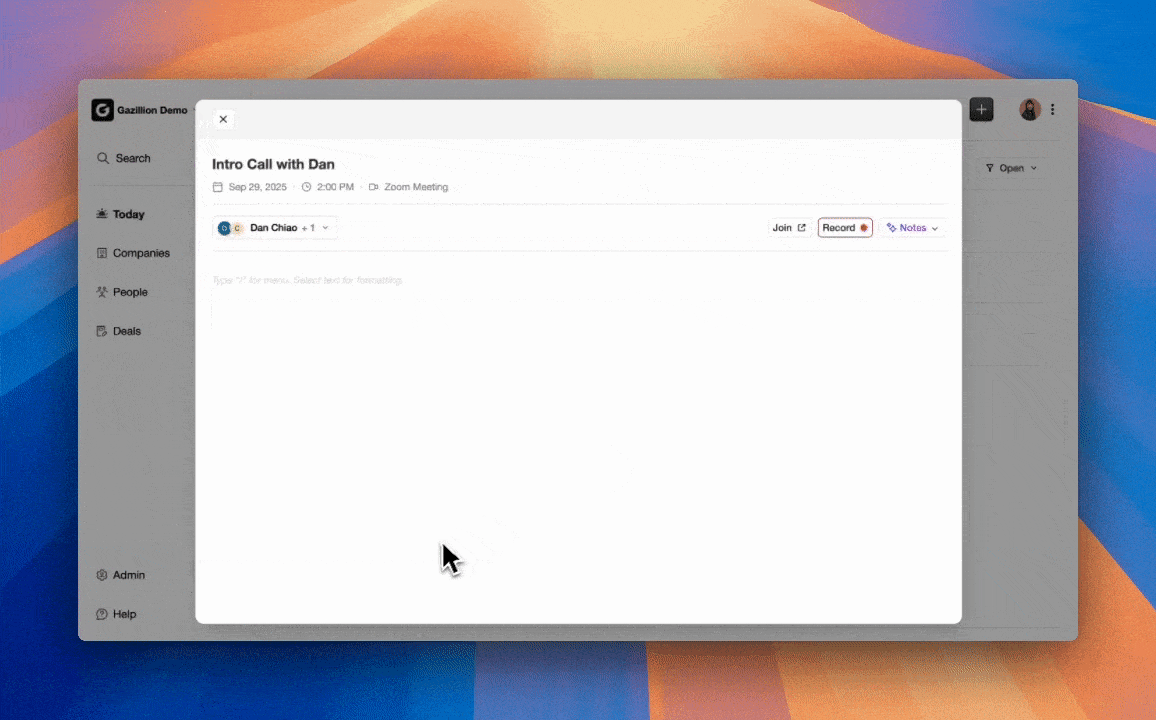
Frontline usability versus manager visibility. CDPs serve data teams and marketing operations. CRMs serve sales managers who need pipeline views, yet those views only stay accurate when reps enter data consistently. An agent layer resolves this tension by capturing ground-truth data from emails, calendars, and call transcripts automatically, so managers gain accurate visibility without taxing reps.
Integration and stack consolidation. Standalone CDPs use predictable subscription pricing but can duplicate existing internal data infrastructure. Total CDP cost of ownership includes implementation, data engineering headcount, connector licensing, training, and ongoing maintenance, which often exceeds initial license pricing.
Total cost of ownership including hidden maintenance. A traditional CDP plus CRM combination introduces significant monthly costs along with ongoing data engineering and storage fees. Organizations with mature enterprise data architecture practices can eventually lower data management costs compared with less mature peers. Reaching that maturity, however, requires significant phased investment first.
Best-Fit Architectures by Company Size and Maturity
Small to mid-market teams (1–200 employees). A full enterprise CDP rarely makes financial sense. Teams that prioritize marketing velocity and lack extensive engineering resources often benefit from standalone CDPs, yet even those introduce implementation overhead that agent-powered CRMs now remove. Teams already committed to Salesforce or HubSpot gain the most from an agent companion layer that fixes data quality without a platform migration.
True enterprise (200+ employees, complex data environments). Companies with established data engineering capacity and analytics teams gain more from warehouse-native architectures. Regulated sectors such as finance, healthcare, and telecommunications benefit from warehouse-native CDPs with smoother compliance reporting and access controls. Coffee does not target heavily regulated enterprises that require multi-year security reviews.
Fresh-start teams versus Salesforce or HubSpot–committed teams. Teams without an existing CRM investment can deploy Coffee’s standalone AI-first CRM and skip legacy architecture entirely. Teams with Salesforce or HubSpot already embedded can deploy Coffee as a companion app, preserve existing workflows, and let the agent handle data quality.
Determine whether Coffee’s standalone CRM or Salesforce/HubSpot companion model fits your operating constraints.
Operational and Long-Term Ownership Costs
Cross-functional ownership represents the most underestimated cost in both architectures. Enterprise data architecture programs require a full dedicated team including 1–2 architects, 2–4 data engineers, 1 governance lead, and 1 data steward per priority business domain, which often exceeds software spend. CRM deployments carry a different but persistent burden, because they require ongoing admin headcount for configuration and hygiene. Beyond these staffing needs, both approaches create change management obligations that software vendors rarely price into proposals.
Data-hygiene drift appears as a predictable failure mode for standalone CRMs. Without an agent enforcing capture discipline, agentic AI remains only as effective as underlying data quality, a point Gartner analyst Irina Guseva reinforced in 2025 while noting that AI amplifies the need for clear ownership and integration discipline. Vendor dependence also grows with complexity, since embedded CDPs can be easier to use, yet migrating off them later is more disruptive than swapping a single connected channel from a standalone CDP.
Risks and Limitations to Weigh
Incomplete automation. Only 14% of organizations have progressed AI agent pilots to partial or full-scale implementation as of 2025–2026. Automation gaps remain, and any architecture that promises full autonomy without process redesign will underdeliver.
Overbuying CDP capability. Enterprise CDP annual licenses can reach substantial levels depending on scale. Most mid-market teams lack the profile volume or engineering capacity to extract value proportional to that spend.
Underestimating implementation effort. Selecting a CDP that cannot scale can become a costly mistake, because migrating from one CDP to another disrupts operations and doubles setup costs. The same risk appears in CRM migrations triggered by adoption failure.
Software does not fix process problems. Forrester Principal Analyst Joe Cicman stated in the 2025 DXP Wave that agentic AI increases the importance of governance, skills, and change management, making organizational readiness, not software capability, the key factor for safely running autonomous workflows at scale.
Decision Framework for Matching Architecture to Constraints
This priority matrix connects your constraints to the architecture that fits best:
- Engineering headcount available (3+ FTEs dedicated to data): Warehouse-native or composable CDP becomes viable, so evaluate Snowflake-based architectures.
- No dedicated data engineering team: Standalone CDP overhead will exceed value, so evaluate an agent-powered CRM or embedded CDP.
- Already on Salesforce or HubSpot with low adoption: Platform migration carries high risk, so deploy an agent companion layer to fix data quality in place.
- Starting fresh, 1–20 employees: Skip legacy CRM and deploy an AI-first standalone CRM with agent-managed data capture.
- Regulated industry (healthcare, finance) with 200+ employees: Choose a warehouse-native CDP with strict governance controls, because Coffee does not fit this profile.
- Mid-market RevOps team needing pipeline accuracy without CDP overhead: Use an agent-powered hybrid to gain unified data quality at a fraction of CDP total cost of ownership.
See if Coffee’s standalone or companion deployment model fits your constraints
What Is the Difference Between CRM and Customer Data Platform?
A CRM acts as a system of record for known contacts, stores sales calls, support tickets, and deal stages, and relies on humans to enter and maintain that data. A CDP automatically ingests behavioral, transactional, and interaction data from every digital touchpoint and resolves it into persistent, unified customer profiles for AI activation. In 2026, a third category has emerged: AI-agent layers that perform the data-capture and unification work of a CDP but operate inside or alongside an existing CRM, which removes the need for a separate platform. Coffee operates in this third category and functions as either a standalone AI-first CRM or a companion agent on top of Salesforce or HubSpot.
What Are the Disadvantages of Enterprise CDP and Standalone CRM?
Enterprise CDPs carry substantial implementation costs before license fees, longer deployment timelines for enterprise setups, significant ongoing engineering headcount requirements, and non-linear cost escalation as sync volume and destination count grow. PII copied across multiple vendor systems expands compliance obligations. Standalone CRMs fail because they depend on manual data entry that sales reps consistently deprioritize, and 71% of reps report spending too much time on data entry, which leaves only 35% of their time for selling. The result includes data-quality degradation, shadow CRMs in spreadsheets, and pipeline forecasts that managers cannot trust. Both architectures share the same root problem, because neither closes the data-quality loop automatically.
How Much Do CDP and CRM Implementations Cost and How Long Do They Take?
Enterprise CDP implementation introduces significant costs that depend on data complexity and integration scope, separate from annual license fees that vary with scale. Deployment timelines often span multiple months for enterprise setups with phased rollouts. Composable CDPs require a mature data warehouse first, so organizations without one face additional time and engineering cost. For context, Salesforce Enterprise lists at $175 per user each month and Unlimited at $350 per user each month, with AI add-ons layered on top. An agent-powered hybrid like Coffee deploys in days to weeks through pre-built integrations, with seat-based pricing that includes unlimited agent labor and no separate infrastructure fees.
When a Hybrid Architecture Delivers the Best Outcome
A hybrid architecture delivers the best outcome when an organization needs unified data quality but cannot justify CDP engineering overhead or timeline. Typical conditions include an existing Salesforce or HubSpot investment that leadership will not abandon, a RevOps or sales team without dedicated data engineering resources, a need for pipeline accuracy that manual CRM entry cannot support, and a compliance requirement such as SOC 2 Type 2 and GDPR that rules out unvetted point solutions. Coffee’s dual deployment model addresses both entry points, because it operates as a standalone AI-first CRM for teams of 1–20 employees or as a companion agent layer for mid-market teams already committed to Salesforce or HubSpot. The agent captures ground-truth data from emails, calendars, and call transcripts, writes enriched records back to the primary CRM, and delivers pipeline intelligence without a separate CDP implementation or additional engineering headcount.
Conclusion and Recommended Next Step
Enterprise CDPs deliver powerful unification capabilities at a cost and complexity that most mid-market teams cannot absorb. Standalone CRMs offer lower entry costs but reproduce the same data-quality failures at scale. The practical middle path uses an AI-agent layer that closes the data-quality loop automatically, captures structured and unstructured data, enriches records, and surfaces pipeline intelligence without a platform migration or a dedicated data engineering team. For RevOps leaders and Heads of Sales evaluating architecture decisions in 2026, the central issue is whether the architecture they choose can guarantee good data in without depending on human compliance. Determine whether Coffee’s standalone CRM or Salesforce/HubSpot companion model fits your operating constraints.
Frequently Asked Questions
Can Coffee replace Salesforce or HubSpot entirely?
For small to mid-sized teams of 1–20 employees, Coffee’s standalone AI-first CRM is designed as a complete replacement for legacy platforms. It handles contact creation, activity logging, pipeline management, meeting intelligence, and forecasting through an autonomous agent, which removes the need for Salesforce or HubSpot. For larger teams already deeply committed to Salesforce or HubSpot, Coffee operates as a companion app rather than a replacement. The agent connects through a simple authentication, captures data from emails, calendars, and calls, enriches records, and writes insights back to the existing system of record. This preserves existing workflows, quotas, required fields, and forecasting configurations while fixing the data-quality problem that makes those platforms unreliable.

How does Coffee handle data security and compliance?
Coffee maintains SOC 2 Type 2 and GDPR compliance. Data ingested by the Coffee Agent, including emails, calendar events, and call transcripts, is not used to train public AI models. This makes Coffee a viable option for mid-market teams that must demonstrate compliance to enterprise customers or operate under data-processing agreements. For organizations in heavily regulated industries such as healthcare or finance that require multi-year security reviews or custom data residency configurations, Coffee does not represent the appropriate fit, and those teams should evaluate warehouse-native CDP architectures with dedicated governance controls.
What does Coffee actually automate, and what still requires human input?
The Coffee Agent automates contact and company creation from email and calendar data, activity logging, meeting recording and transcription, post-call summary and follow-up drafting, pipeline change tracking, data enrichment through licensed partners, and prospect list building through natural language commands. It also identifies anonymous website visitors and matches them to named individuals with enriched profiles. Human input remains essential for strategic decisions such as approving follow-up emails before sending, reviewing pipeline recommendations, and setting outreach priorities. The agent handles administrative execution, and the rep retains control over judgment calls. Broader stack integrations beyond Google Workspace, Microsoft 365, and native Salesforce or HubSpot sync currently run through Zapier, with deeper native integrations on the product roadmap.
How is Coffee priced compared to a traditional CRM or CDP stack?
Coffee uses seat-based pricing where the cost covers human users and the agent’s labor without separate metering for LLM usage, process volume, or data events. This contrasts with enterprise CDP pricing, which scales with active profile count, event volume, integration count, and feature tier, and with Salesforce’s per-user model that adds AI capabilities as separate paid add-ons. For teams evaluating total cost of ownership, Coffee removes the need for separate enrichment tools like ZoomInfo or Apollo, standalone conversation intelligence tools like Gong, and manual pipeline reporting exports, which consolidates multiple line items into a single seat-based fee.
What happens to existing CRM data when Coffee is deployed as a companion app?
When deployed as a companion app on Salesforce or HubSpot, Coffee does not migrate or overwrite existing records. The agent connects through a standard authentication flow, reads existing contact and deal data to establish context, and then begins writing new enriched data such as activity logs, meeting summaries, enriched contact fields, and pipeline updates back into the existing system of record. Historical data remains in place. The agent’s primary function is to ensure that every new interaction is captured automatically and every record stays current without rep-driven data entry. Teams retain their existing Salesforce or HubSpot configurations, including custom fields, required fields, forecasting categories, and quota structures.