Written by: Doug Camplejohn, CEO & Co-Founder, Coffee
Key Takeaways
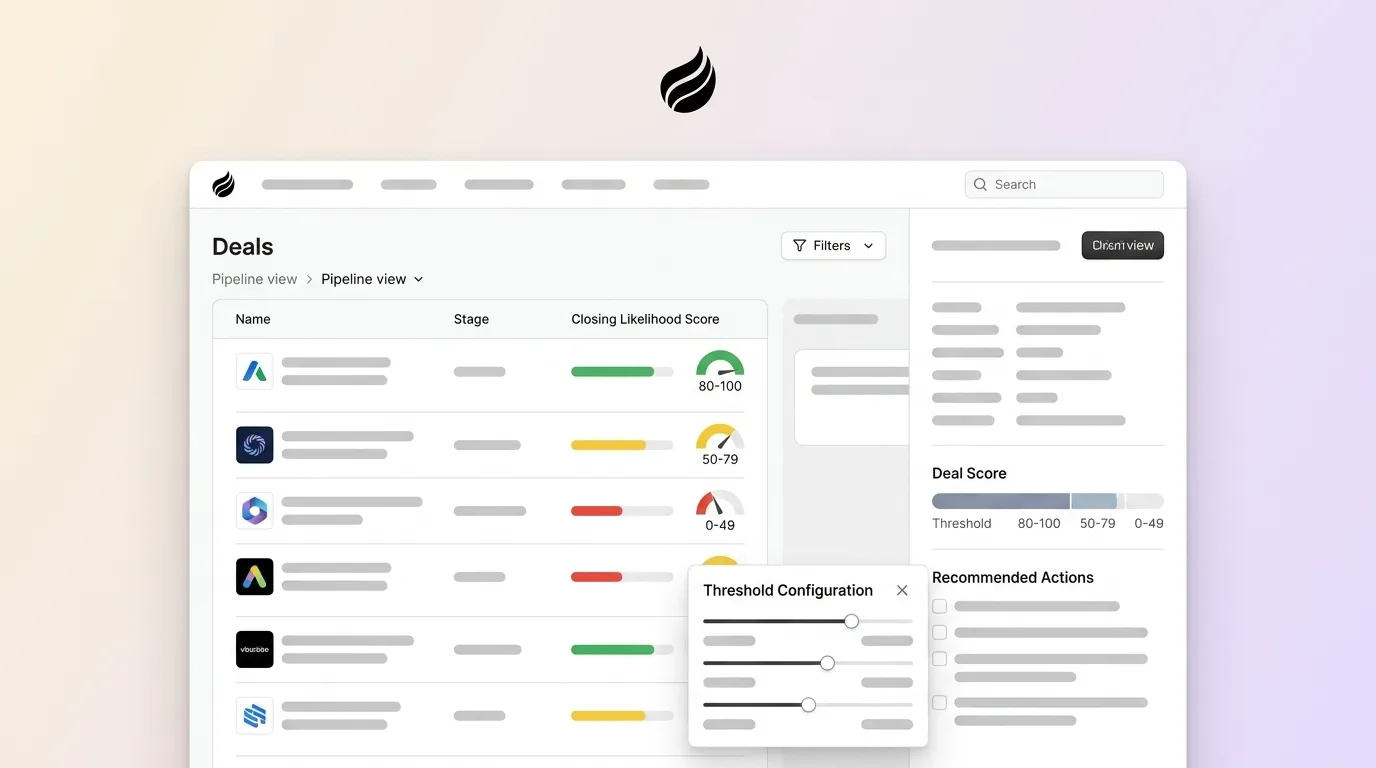
- Deal scoring thresholds on a 0–100 scale route opportunities by triggering actions like immediate outreach, nurture sequences, or disqualification at defined cutoffs.
- Clear thresholds turn continuous scores into specific operational decisions, which improves pipeline prioritization and forecast accuracy when the data is reliable.
- Threshold design always balances volume and quality. Low thresholds increase handoffs but lower conversion, while high thresholds improve quality and reduce coverage.
- Poor CRM data quality is the leading cause of threshold failure. Incomplete or stale records create unreliable scores and misdirected sales effort.
- Ready to automate the data foundation your thresholds depend on? Explore Coffee’s pricing and plans today.
How deal scores quantify closing likelihood
A deal score is a composite numeric value, typically on a 0–100 scale, that represents how likely an opportunity is to close. The score comes from a weighted combination of firmographic fit, behavioral signals, engagement recency, and qualification criteria. Sales teams that prioritize by score can improve win rates by focusing effort where it produces the highest return.
In practice, a deal score aggregates inputs such as company size, job title, intent signals, and CRM activity into a single number that maps to a defined action. Higher-scoring accounts often move through the sales cycle faster and close at larger average deal sizes.
Deal scores are only as reliable as the data feeding them. When CRM records are incomplete or stale, the score reflects a fiction, and reps act on that fiction at scale.
Automate the data entry that makes deal scores trustworthy with Coffee.
How thresholds turn scores into sales actions
A threshold is the minimum score a deal must reach before a specific action triggers. Thresholds translate a continuous score into a binary decision such as act now, nurture, or disqualify. Without defined thresholds, a score remains just a number with no operational consequence.
Threshold design has evolved significantly since 2024. Traditional lead scoring relied on static, predetermined point values for criteria such as job title or form submissions and failed to account for evolving buyer behavior or market shifts. Modern dynamic scoring models update thresholds continuously as new behavioral data arrives. A pricing page visit or a webinar registration can shift a deal from the orange tier to the yellow tier in real time.
This real-time responsiveness drives the performance gains that AI scoring delivers. According to McKinsey research, AI sales tools can increase leads by more than 50%, and the shift from static rules to dynamic thresholds is the primary mechanism behind that lift.
Common 2026 threshold benchmarks by function:
- MQL threshold: 60–75 points
- SQL threshold: higher than MQL
- Hot lead threshold: 80+ points
How deal scoring thresholds run inside your CRM
Thresholds operate as routing rules inside a CRM. When a deal’s composite score crosses a defined cutoff, an automated workflow fires. An alert routes to an AE, a sequence enrolls the contact, or a deal stage advances. HubSpot notes that lead-scoring thresholds can trigger deal creation or stage advancement while account-based marketing groups contacts into target accounts for coordinated engagement.
Scoring models draw from two categories of inputs:
- Structured data: Firmographics such as company size, industry, revenue, role authority like C-level vs. coordinator, deal size, and CRM field values.
- Unstructured data: Email content, call transcripts, meeting notes, and intent signals from behavioral tracking.
B2B scoring models should weight firmographic fit, role authority, behavioral signals, and engagement recency when setting conversion-predictive thresholds. A practical weighting example on a 100-point scale assigns 30 points to job title, 30 to company size, 25 to industry alignment, and 15 to behavioral engagement.
AI scoring systems update scores the moment new information arrives, such as a pricing page visit or webinar attendance, which lets thresholds trigger immediate actions instead of waiting for weekly or monthly reviews. Real-time updates alone create a new problem because deals that scored high months ago can remain at the top of the queue even when engagement has gone cold. That is why score decay is equally important. Applying a 25% monthly score decay without new activity keeps thresholds relevant by giving recent engagement priority over stale high-scoring leads.
How to balance the main threshold trade-offs
Every threshold decision involves a trade-off between pipeline volume and conversion quality, and that tension shows up across several dimensions that work together.
The first dimension is threshold level. Low thresholds increase handoff volume but route lower-quality deals to reps. If the MQL-to-opportunity conversion rate drops below 20%, the scoring threshold may be set too low. High thresholds improve conversion rates but reduce pipeline coverage and can keep emerging opportunities in nurture for too long.
The second dimension is model complexity. Model complexity is a compounding risk. Scoring models with more than five to seven criteria cause leads to cluster too closely in score and reduce the model’s usefulness for prioritization. Teams must balance enough detail to separate quality from noise against simplicity that reps can understand and trust.
The third dimension is time and change. Static vs. dynamic models reflect this. Fixed thresholds are easier to manage and explain but degrade as markets and buyer behavior shift. Quarterly model reviews and retraining improve prediction accuracy at the cost of added operational effort.
The fourth dimension is coverage strategy. Standardization vs. specialization matters here. One universal threshold is easier to administer, but segment- or source-specific thresholds can be more accurate for different deal types or industries. Teams should decide which segments justify specialized treatment based on revenue impact.
Frequent model review ties these dimensions together. Organizations that review scoring models on a regular cadence see higher ROI from marketing investments than those that review less often. Governance cadence is not optional. It is a structural requirement for threshold reliability.
Readiness checklist for deal scoring thresholds
Teams should evaluate readiness across five dimensions before configuring thresholds.
- Data volume: A reliable ICP scoring model can be built from a cohort of at least 20 closed-won deals. Implementations with 30–50 closed-won deals can refine an ICP or support a usable scoring model when the right signals are tracked.
- Data completeness: If more than 40% of CRM records are missing key fields such as industry, company size, or deal stage dates, data hygiene must be fixed before training a scoring model. Otherwise reps will ignore the resulting scores within a week.
- Historical analysis: Teams should export and analyze the last 12–24 months of closed-won and closed-lost deals to identify patterns in company size, industry, title, engagement behavior, and buying signals.
- SLA alignment: Scoring thresholds deliver value only when paired with a shared SLA between marketing and sales that defines exact actions at each threshold. The SLA should specify what score triggers an MQL, when sales must accept or reject a lead, and expected follow-up time.
- Feedback loop: Feedback loops with sales teams help detect when thresholds are too permissive or too strict. Tracking engagement scores alongside rep-reported lead quality issues and conversion outcomes keeps the SLA and the model aligned in practice.
Why deal scoring thresholds break in real life
The primary cause of threshold failure is poor data quality. A score computed from incomplete, stale, or manually entered CRM data does not reflect deal reality. It reflects whatever a rep happened to log last quarter.
The scale of the problem is significant.
- 77% of organizations rate their data quality as average or worse, an 11-point decline from prior years. Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data.
- Gartner estimates that dirty data costs companies an average of $15 million annually in operational waste.
- Sellers and sales reps waste over 27% of their time dealing with inaccurate CRM information and bad data quality that could otherwise go toward booking meetings and closing pipeline.
- Few RevOps and sales leaders agree they have the right data to forecast accurately.
- A Forrester 2026 B2B predictions report forecasts more than $10 billion in losses tied to ungoverned AI in B2B sales and marketing because AI tools are deployed on top of unvalidated CRM data.
These losses compound because the failure mode is not just inaccuracy. It is confident inaccuracy. An agent querying stale or inaccurate data does not produce a worse answer. It produces a confident wrong one. In benchmark tests, SQL agents on raw unenriched tables show lower accuracy on business questions. Improving the underlying metadata without changing the AI model can significantly improve accuracy.
Organizations investing heavily in data foundations show 70% AI revenue satisfaction vs. 28% for low investors, a 2.5× gap. The threshold is not the problem. The data feeding it is.
Step-by-step plan to implement reliable thresholds
A four-phase implementation produces thresholds that hold up under real pipeline conditions.
- Discovery (Weeks 1–2): Export 12–24 months of closed-won and closed-lost deals. Identify the lowest score among converted deals as the practical MQL floor. Set MQL and SQL cutoffs around that observed boundary. Apply negative scoring to disqualifying signals such as competitor domains, personal emails in B2B contexts, and unsubscribes.
- Pilot (Weeks 3–6): Set the initial sales handoff threshold at 70–80 points, measure conversion rates for 30 days, and adjust based on actual conversion data. Start conservatively to build rep confidence before lowering thresholds.
- Validation (Month 2): Compare scored predictions against actual outcomes monthly and check whether top-tier leads convert at a meaningfully higher rate than mid-tier leads. If they do not, recalibrate the weighting model.
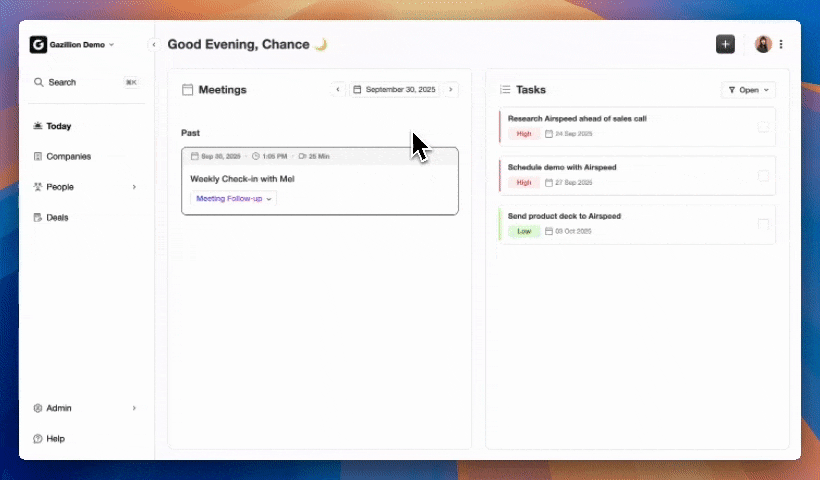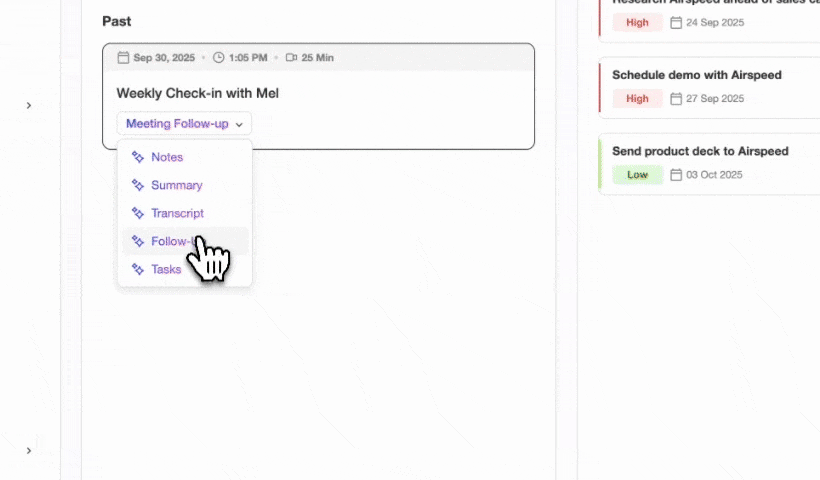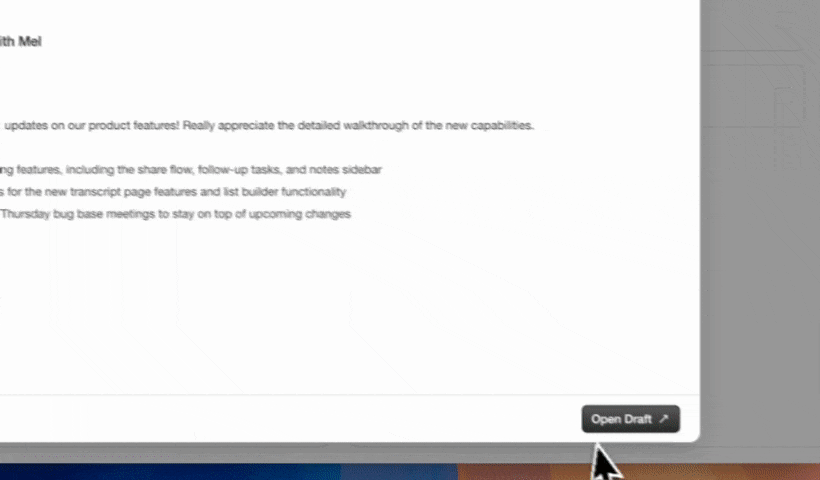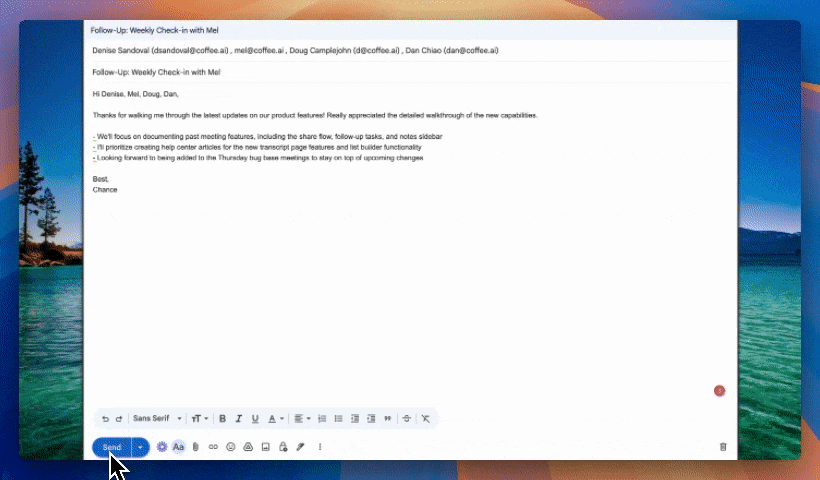
- Measurement (Ongoing): Track MQL-to-opportunity conversion rate, pipeline velocity by tier, and win rate by score band. Teams using BANT scoring models have reported reduced time on unqualified conversations, higher close rates, and shorter sales cycles.
None of these steps produce durable results without clean, continuously updated CRM data. That is where Coffee’s AI agent operates. Coffee’s Companion App deploys an autonomous agent on top of existing Salesforce or HubSpot instances. It automatically captures emails, call transcripts, and calendar activity to keep every deal record current, without manual entry from reps. Clean data in creates reliable scores out.
See how Coffee keeps your CRM data current for accurate thresholds.
Frequently Asked Questions
What is the difference between a deal scoring model and deal scoring thresholds?
A deal scoring model is the underlying framework that assigns weighted point values to deal attributes such as firmographic fit, behavioral signals, engagement recency, and qualification criteria to produce a composite score. Deal scoring thresholds are the cutoff points applied to that score to trigger specific actions. The model determines what the score is. The thresholds determine what happens next.
Both components must be calibrated together. A well-designed model with poorly set thresholds routes deals incorrectly, and well-set thresholds built on a flawed model create the same problem.
How often should deal scoring thresholds be reviewed and updated?
Teams should review thresholds on a quarterly cadence at minimum, with immediate recalibration after significant shifts in conversion patterns, new product launches, or changes in ICP definition. Quarterly reviews let teams compare predicted outcomes against actual closed-won and closed-lost data, identify score bands that are over- or under-performing, and adjust weightings accordingly.
Annual reviews are not enough because buyer behavior, market conditions, and competitive dynamics shift faster than a yearly cycle can capture. Teams should also apply time-based score decay, typically 25% monthly for inactive deals, to prevent stale high scores from distorting prioritization between formal review cycles.
Why do deal scoring thresholds produce unreliable results even when the model logic is sound?
The most common cause is poor underlying data quality. A scoring model is only as accurate as the CRM records feeding it. When deal stage dates are missing, contact roles are blank, or activity logs are incomplete because reps did not manually enter them, the model computes a score against a partial picture of the deal.
The resulting threshold routing is confidently wrong. It sends AEs into deals that look qualified on paper but are not in reality. The fix is not a better model. It is better data. Automating the data entry layer, and capturing emails, calls, and calendar events without human intervention, ensures the model always computes against a complete, current record.
What is dynamic deal scoring and how does it differ from static thresholds?
Static thresholds assign fixed point values to predefined criteria and do not change unless a human manually updates the rules. Dynamic deal scoring uses machine learning to continuously update both the score and the weighting of individual signals based on observed conversion outcomes.
When a new behavioral pattern, such as a pricing page visit correlating strongly with closed-won deals, emerges in the data, a dynamic model incorporates that signal automatically. Thresholds in a dynamic system can also adjust based on team capacity and market conditions. The system can surface only the highest-scoring deals when pipeline is full and broaden coverage when it is thin.
Dynamic scoring requires a minimum data foundation of roughly 100–200 historical leads with known outcomes before the model produces reliable predictions.
How does Coffee’s Companion App improve deal scoring threshold accuracy for Salesforce and HubSpot users?
Coffee’s Companion App deploys an AI agent directly on top of an existing Salesforce or HubSpot instance. The agent automatically captures and logs every email, call transcript, meeting summary, and calendar event associated with a deal, without requiring reps to manually enter data.
This continuous, automated data capture removes the primary cause of threshold failure, which is incomplete and stale CRM records. Because every deal record reflects the full, current state of the opportunity, the scoring model computes against accurate inputs and threshold routing reflects pipeline reality. Coffee also enriches records with firmographic data, tracks activity recency autonomously, and surfaces pipeline changes week over week, which gives RevOps teams the data foundation required to trust their thresholds and their forecasts.
Conclusion: thresholds that match reality
Deal scoring thresholds on a 0–100 scale provide a practical framework for pipeline prioritization. Green-tier deals from 75–100 receive immediate AE attention. Yellow-tier deals from 50–74 enter structured SDR sequences. Orange-tier deals from 25–49 stay in nurture, and red-tier deals from 0–24 are suppressed. The framework is straightforward. The execution is not.
Threshold reliability depends entirely on data quality. Incomplete CRM records, stale deal stages, and missing activity logs corrupt the score before the threshold logic ever runs. With three-quarters of organizations struggling with data quality and a 2.5× satisfaction gap between high and low data investors, the direction is clear. Thresholds built on clean data produce forecasts that hold.
Organizations that invest in strong data foundations see far higher AI revenue satisfaction. The framework above provides the benchmarks. Coffee provides the data quality that makes them work.
Start with Coffee today and build deal scoring thresholds your team can trust.


