Written by: Doug Camplejohn, CEO & Co-Founder, Coffee
Key Takeaways
- The Claude Messages API uses a single POST endpoint that supports streaming, tool use, and structured outputs once your API key and SDK are ready.
- Store your Anthropic key in an environment variable, install the SDK, and monitor rate-limit headers so production traffic avoids 429 errors.
- Python and Node.js examples follow the same pattern for creating messages, tracking token usage, and running streaming or tool-calling loops.
- Prompt caching, batching, and model selection between Opus and Sonnet give you the main controls for managing cost at scale.
- Teams can script custom Claude prompts and route results directly into CRM records with Coffee—explore Coffee’s API access.
Get Your Claude API Key
Create an account at platform.claude.com and generate an API key under API Keys. Keys are scoped to an organization and inherit that organization's rate-limit tier. Store the key in an environment variable, not in source code. The current most capable generally available model is claude-opus-4-8, released May 28, 2026.
Install the Official SDKs
Install the SDK and configure the environment variable before you write any integration code.
# Python pip install anthropic # Node.js npm install @anthropic-ai/sdk # Both environments — add to .env or shell profile export ANTHROPIC_API_KEY="sk-ant-..." The SDK reads ANTHROPIC_API_KEY automatically. You only pass a key explicitly in the client constructor when you need per-request key rotation.
Claude API Integration with Python
With the SDK installed and your key configured, you can send your first message from Python.
import anthropic client = anthropic.Anthropic() response = client.messages.create( model="claude-opus-4-8", max_tokens=1024, messages=[{"role": "user", "content": "Summarize this deal note: ..."}] ) print(response.content[0].text) print("Input tokens:", response.usage.input_tokens) print("Output tokens:", response.usage.output_tokens) Gotcha: rate-limit headers. Every response carries headers such as anthropic-ratelimit-input-tokens-remaining, which enable per-request self-throttling. Log these headers in development so you understand token pressure before you hit a 429 in production. A single large-context request can exhaust token limits even when request count is low.
Claude API Integration with Node.js
The Node.js client follows the same pattern as Python for sending messages and reading usage.
import Anthropic from "@anthropic-ai/sdk"; const client = new Anthropic(); const response = await client.messages.create({ model: "claude-opus-4-8", max_tokens: 1024, messages: [{ role: "user", content: "Summarize this deal note: ..." }], }); console.log(response.content[0].text); console.log("Input tokens:", response.usage.input_tokens); console.log("Output tokens:", response.usage.output_tokens); Gotcha: token-count behavior. Cache-read input tokens do not count against the ITPM rate limit, so a high cache-hit rate effectively multiplies your throughput headroom. Always read usage.cache_read_input_tokens separately from usage.input_tokens when you calculate actual cost and rate-limit exposure.
Streaming Responses in Python and Node
Python streaming:
with client.messages.stream( model="claude-opus-4-8", max_tokens=1024, messages=[{"role": "user", "content": "Draft a follow-up email."}] ) as stream: for text in stream.text_stream: print(text, end="", flush=True) final = stream.get_final_message() print("\nTotal output tokens:", final.usage.output_tokens) Node.js streaming:
const stream = await client.messages.stream({ model: "claude-opus-4-8", max_tokens: 1024, messages: [{ role: "user", content: "Draft a follow-up email." }], }); for await (const chunk of stream) { if (chunk.type === "content_block_delta") { process.stdout.write(chunk.delta.text); } } const final = await stream.finalMessage(); console.log("\nTotal output tokens:", final.usage.output_tokens); Gotcha: partial token usage. Token counts finalize only in the message_delta event at the end of a stream. Usage reads during the stream return incomplete values. Capture the terminal event before you log costs or enforce budget caps.
Structured JSON Outputs for CRM Fields
Use a system prompt plus a clear user instruction to enforce a JSON schema. Claude Opus 4.8 has stronger agentic judgment, so schema adherence is more reliable than with earlier models.
# Python — JSON schema enforcement response = client.messages.create( model="claude-opus-4-8", max_tokens=512, system="Return only valid JSON matching this schema: {"name": string, "next_step": string, "confidence": number}", messages=[{ "role": "user", "content": "Extract CRM fields from: 'Met with Alice at Acme, she wants a demo next Tuesday.'" }] ) import json data = json.loads(response.content[0].text) The same pattern applies in Node.js with JSON.parse(response.content[0].text). Validate the parsed object against your schema before you write to any downstream system.
Tool Use with the Messages API
The Messages API tool loop is application-managed. You call Claude, detect stop_reason: "tool_use", execute the tool, append the result, and continue until stop_reason == "end_turn".
# Python — tool-calling loop tools = [{ "name": "lookup_contact", "description": "Fetch CRM contact by email.", "input_schema": { "type": "object", "properties": {"email": {"type": "string"}}, "required": ["email"] } }] messages = [{"role": "user", "content": "What is the last activity for alice@acme.com?"}] while True: response = client.messages.create( model="claude-opus-4-8", max_tokens=1024, tools=tools, messages=messages, ) if response.stop_reason == "end_turn": print(response.content[0].text) break for block in response.content: if block.type == "tool_use": result = lookup_contact(block.input["email"]) # your function messages.append({"role": "assistant", "content": response.content}) messages.append({ "role": "user", "content": [{ "type": "tool_result", "tool_use_id": block.id, "content": result, }], }) break Gotcha: tool_result blocks must appear before text content in the same message, or the API returns a 400 error.
Claude API Error Handling in Production
When any rate limit is exceeded, the API returns a 429 with a retry-after header that identifies which bucket was hit. Use the retry-after header as the primary retry signal. Fall back to exponential backoff with jitter only when the header is absent.
import time, random, anthropic client = anthropic.Anthropic() def call_with_retry(payload, max_attempts=5): for attempt in range(max_attempts): try: return client.messages.create(**payload) except anthropic.RateLimitError as e: retry_after = float(e.response.headers.get("retry-after", 2 ** attempt)) jitter = random.uniform(0, 0.5) time.sleep(retry_after + jitter) raise RuntimeError("Max retry attempts exceeded") Pair retry logic with workload shaping, such as lower concurrency, per-tenant queues, and model-family concurrency caps to avoid amplifying throttling under load. All Opus 4.x model versions share a single rate-limit bucket, so mixing claude-opus-4-7 and claude-opus-4-8 calls does not increase headroom.
Cost Optimization for Claude Workloads
Claude Opus 4.8 is priced at $5 per million input tokens and $25 per million output tokens. Fast Mode runs at $10 and $50 but delivers 2.5× higher output tokens per second at 3× lower cost than fast mode on previous models. Three levers reduce spend materially at scale.
Prompt caching: Prompt caching delivers a 90% discount on cached input tokens after the first message. Cache stable content such as system prompts, tool definitions, and large documents by marking them with cache_control: {"type": "ephemeral"}. Cache-read tokens also bypass ITPM limits, which gives you a cost and throughput benefit.
Batching: Batching related changes into a single prompt costs roughly one-fifth as many tokens as five separate prompts that each reload full context. Use the Batch API for non-latency-sensitive workloads such as nightly enrichment runs.
Model selection: Claude Sonnet 4.6 is priced at $3 input and $15 output per million tokens. This pricing is significantly lower than Opus 4.8 for tasks that do not require maximum reasoning depth. Route classification, summarization, and extraction tasks to Sonnet, and reserve Opus for complex agentic loops.
Production Checklist for Claude Integrations
| Concern | Implementation | Signal to Monitor | Notes |
|---|---|---|---|
| Rate-limit retries | Read retry-after header, then use exponential backoff with jitter as a fallback |
anthropic-ratelimit-*-remaining headers |
Cap total attempts to fail clearly |
| Token tracking | Log usage.input_tokens, usage.output_tokens, and usage.cache_read_input_tokens per call |
Usage and Cost API | Alert at 75% of per-minute peak |
| Conversation memory | Summarize or truncate history before context exceeds budget | Running token count in messages array | A 200K-token conversation re-sends full context every turn |
| Batching | Use Batch API for async workloads and group related prompts | Batch job completion status | Single batched prompt costs ~1/5 of five sequential prompts |
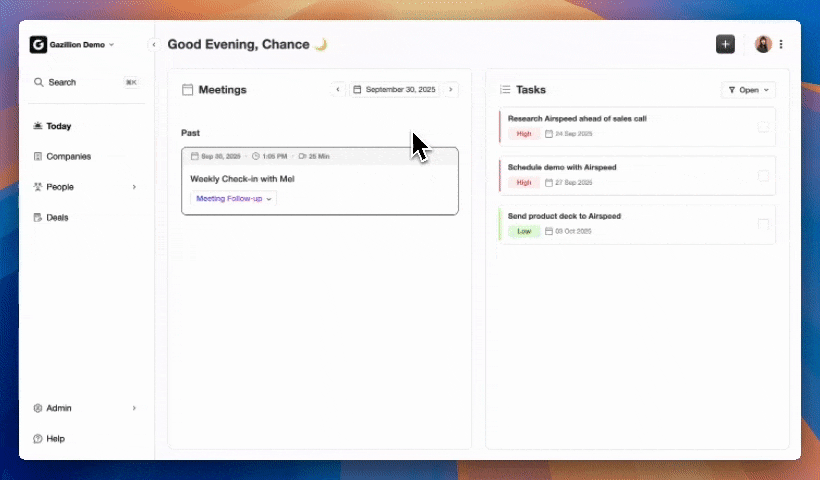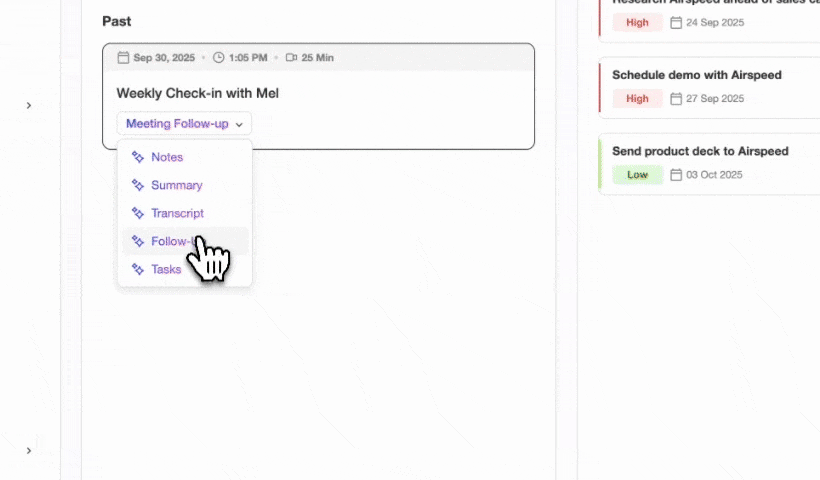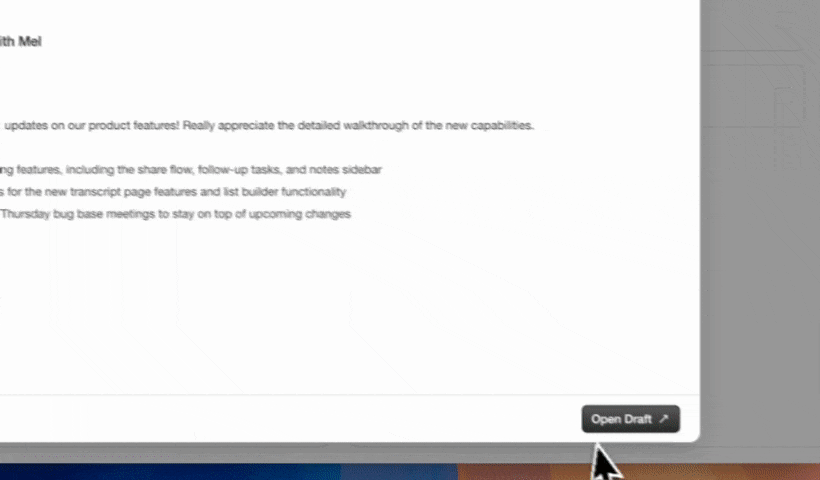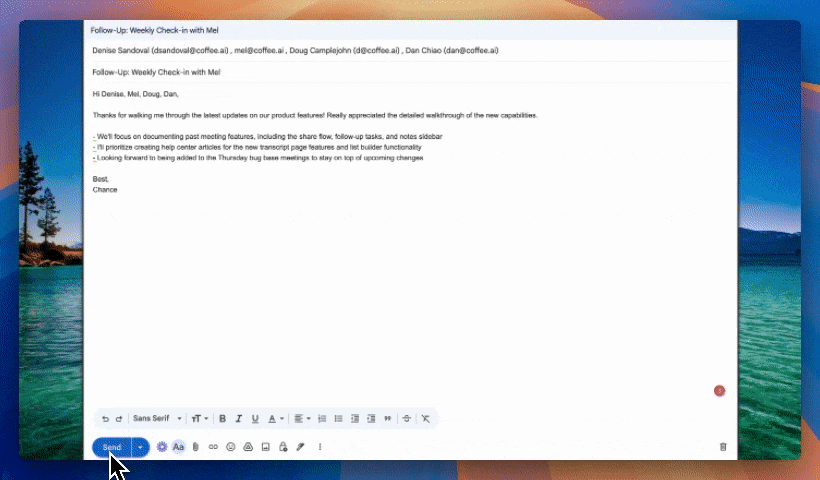
Putting Claude Insights into Your CRM
A working Claude integration produces structured outputs such as contact summaries, deal-stage assessments, and action items from call transcripts. These outputs only create durable value when an agent writes them back to a system of record automatically. Manual copy-paste removes most of the benefit.
An autonomous CRM agent solves this by acting as the consumer of Claude's outputs. When Claude returns a structured JSON object containing a contact name, next step, and confidence score, the agent parses that payload and matches it to the correct CRM record. This matching step ensures enriched fields land on the right contact without human intervention. After the write, the agent logs the interaction timestamp, updates pipeline stage, and preserves the full conversation history in a data warehouse so later field updates do not erase context.
This pattern becomes especially valuable for teams running tool-use loops. Claude can call a lookup_contact tool mid-conversation, receive live CRM data, reason over it, and return a recommended action. The agent then captures both the input context and the recommendation, which creates an auditable record of every AI-assisted decision in the pipeline.
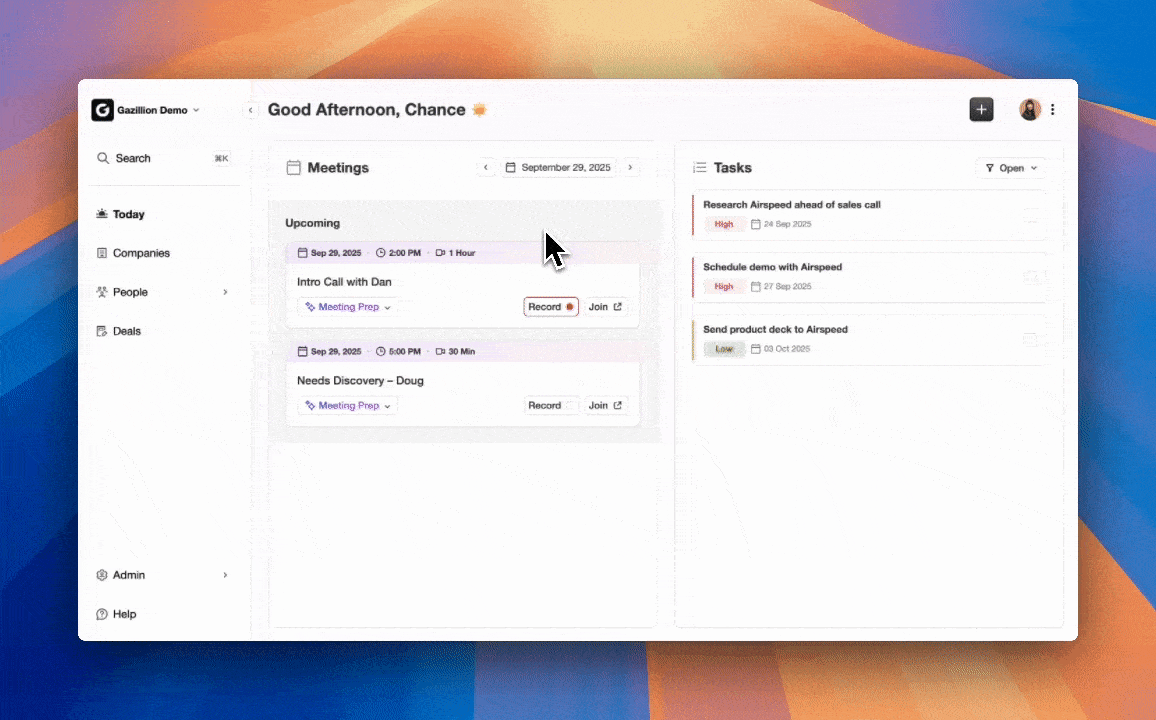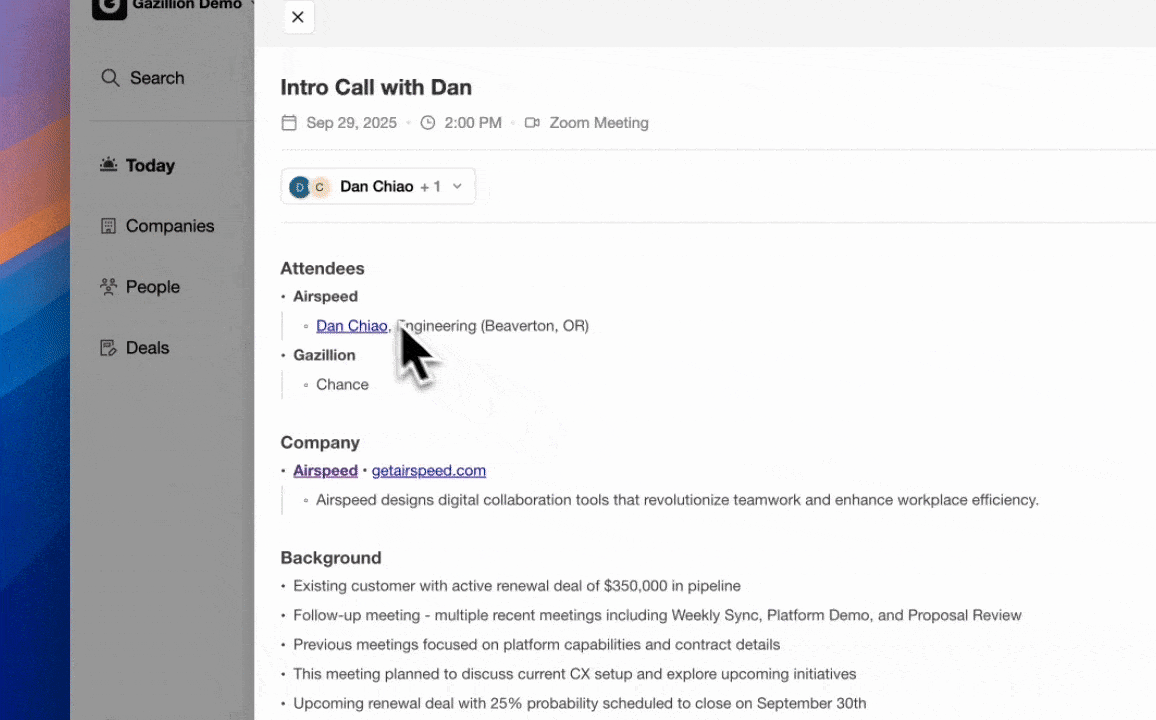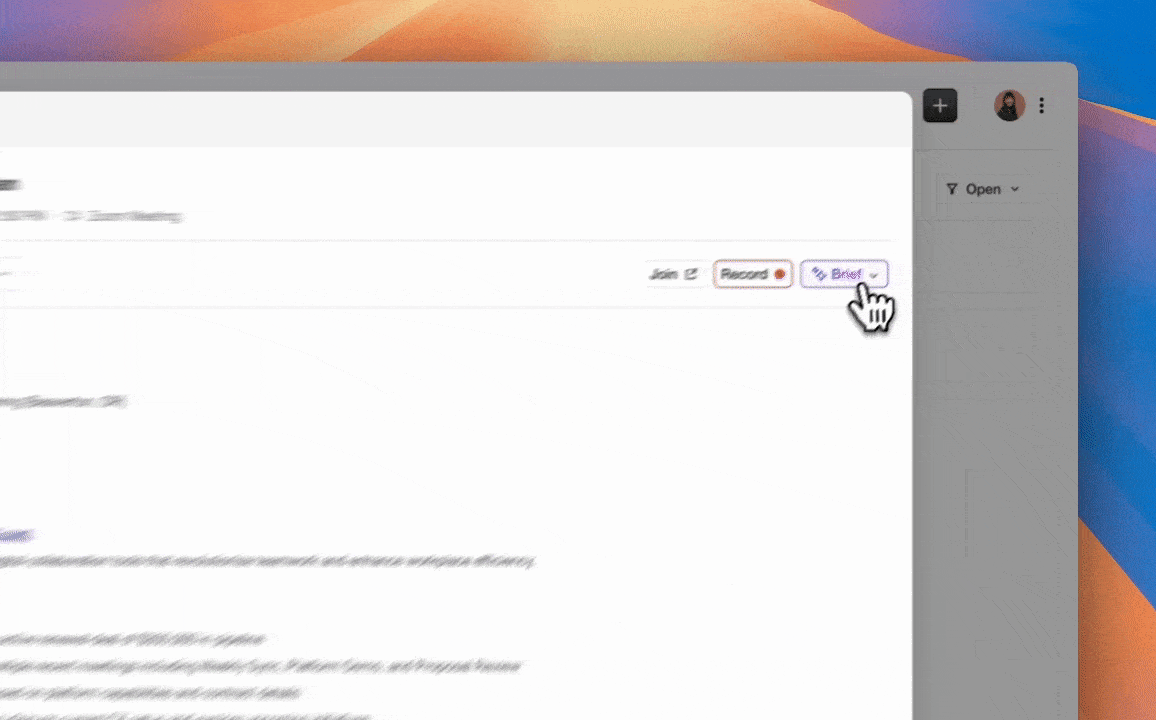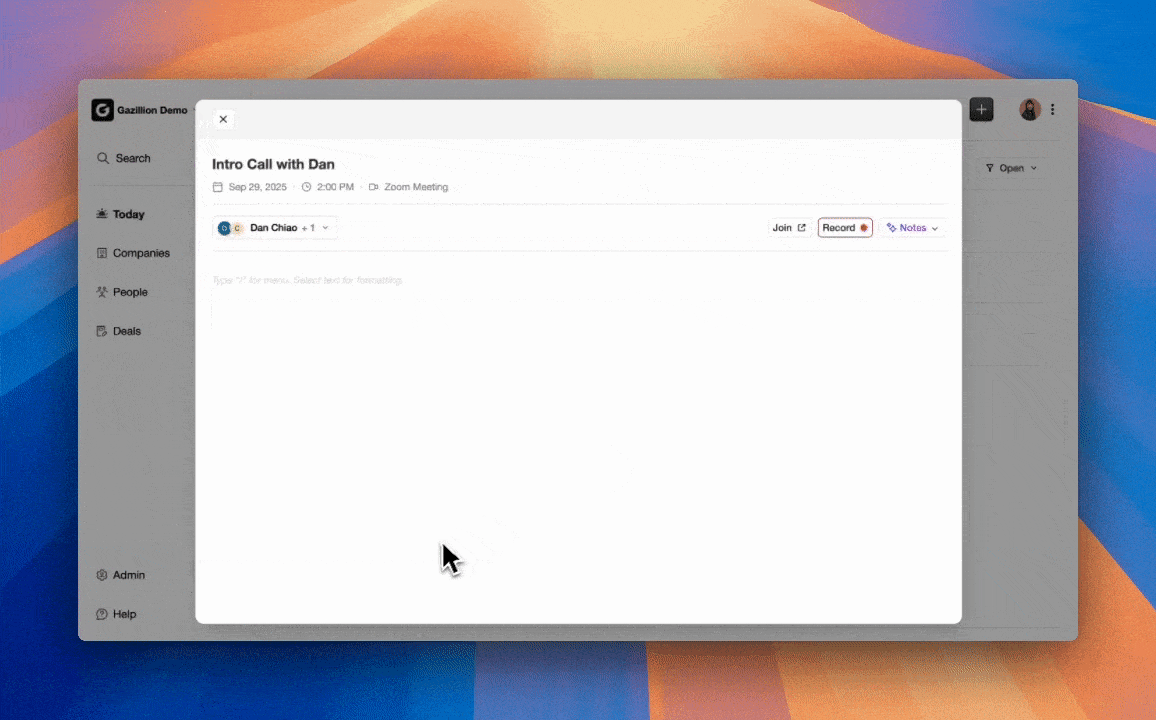
Coffee's autonomous CRM Agent is built for this workflow from end to end. It ingests Claude-generated outputs, enriches contact and company records, logs every interaction from emails and call transcripts, and surfaces pipeline intelligence without a human acting as a data entry clerk. Teams using Coffee's API access can script custom Claude prompts and route the results directly into their CRM records, following the same pattern used by customers generating tens of millions in revenue who rejected Salesforce and HubSpot for requiring too much manual maintenance.
Frequently Asked Questions
Which Claude model should I use for a new production integration in 2026?
Claude Opus 4.8 is the most capable generally available model on the Anthropic Messages API as of June 2026. It supports a 1-million-token context window, 128K output tokens, and includes Fast Mode for latency-sensitive workloads. For cost-sensitive tasks such as classification or summarization, Claude Sonnet 4.6 handles most workloads at a lower per-token price. Route by task complexity instead of defaulting to Opus for every call.
How do I avoid hitting rate limits in a multi-tenant application?
Rate limits on the Claude API are enforced at the organization level across three buckets: requests per minute, input tokens per minute, and output tokens per minute. A small number of large-context requests can exhaust token limits even when request count is low. Implement per-tenant queues, read the rate-limit headers on every response to track remaining quota in real time, and call the Rate Limits API on startup to get current org-level limits instead of hardcoding values. Alert internally when any bucket exceeds 75% of its per-minute peak so you can shed load before you hit a hard 429.
Does prompt caching affect rate-limit calculations?
Yes. As explained in the Cost Optimization section, cache-read input tokens bypass the input-tokens-per-minute rate limit and effectively increase your headroom. At a 70% cache-hit rate, effective ITPM capacity increases by roughly 3.3×. Always log cache_read_input_tokens separately from input_tokens so you can distinguish rate-limit exposure from actual billing cost.
What is the correct way to handle tool_result messages to avoid 400 errors?
When you use the Messages API tool loop, tool_result blocks must appear before any text content in the same message. The control flow is simple: call Claude, detect a stop_reason of tool_use, execute the tool in your application, append the assistant turn containing the tool_use block, then append a user turn containing the tool_result block. Continue this loop until stop_reason equals end_turn. Placing text content before tool_result in the same message returns a 400 error from the API.