Written by: Doug Camplejohn, CEO & Co-Founder, Coffee
Key Takeaways
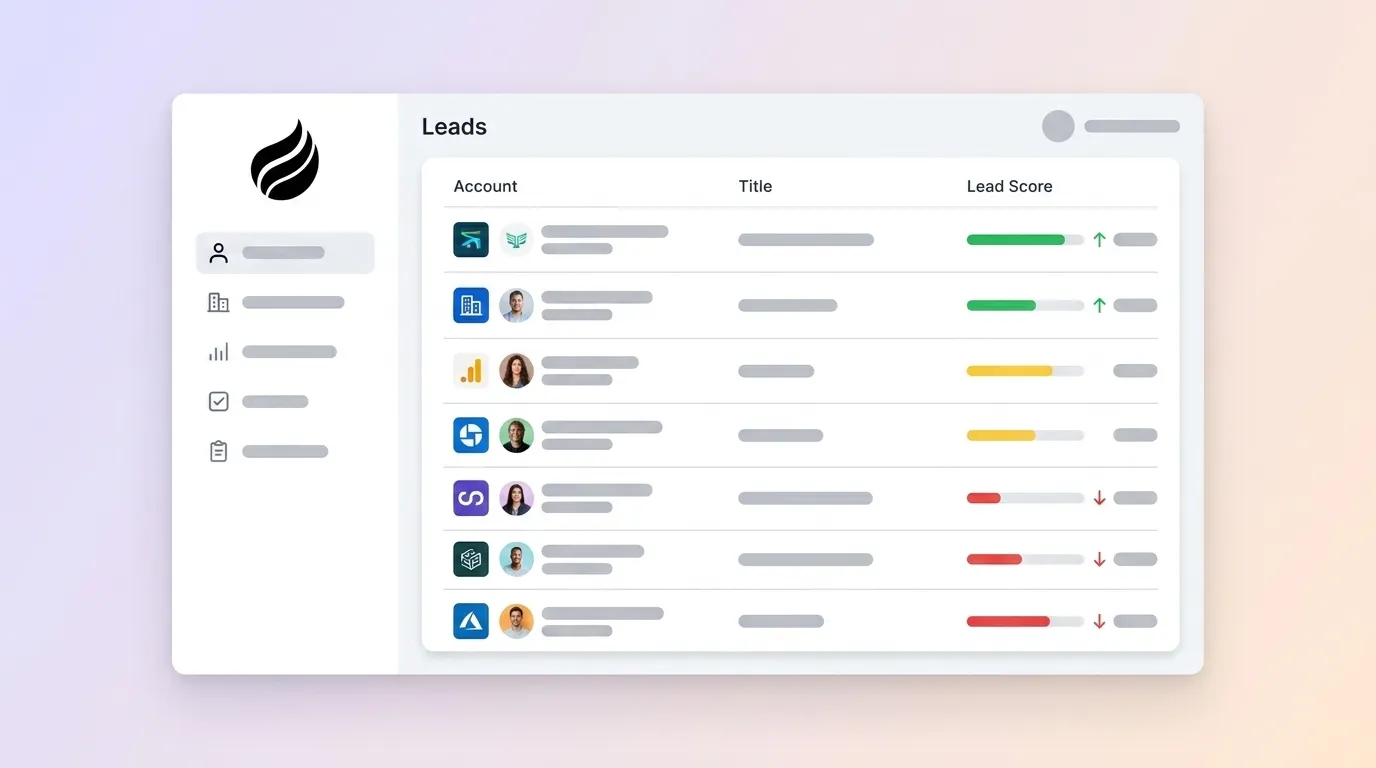
- Lead scoring ranks prospects by combining fit criteria such as job title and company size with intent signals like demo requests and pricing-page visits.
- Multiple models exist, from simple rule-based systems to AI and time-decay approaches, each with clear MQL and SQL thresholds that teams can adapt.
- Negative scoring and time-decay rules remove false positives and keep scores tied to current engagement instead of outdated activity.
- High-quality, automatically captured CRM data underpins every model; incomplete records cause even sophisticated scoring logic to underperform.
- Coffee automatically enriches and logs every record so your scoring models stay accurate. See Coffee’s pricing and keep your data current.
Lead Scoring Model Comparison at a Glance
The table below compares point ranges and qualification thresholds for each model so you can match a framework to your lead volume and deal complexity.
| Model | Point Range | MQL Threshold | SQL Threshold |
|---|---|---|---|
| Rule-Based | 0–100 | 50 | 75 |
| Fit + Intent | 0–120 | 55 | 85 |
| Enterprise / ABM | 0–150 | 60 (MQA) | 85 (MQA Tier A) |
| Negative Scoring | −50 to +100 | 50 net | 75 net |
| Time-Decay | 0–100 (decaying) | 50 | 75 |
| Predictive | 0–100 (ML-weighted) | 60 | 80 |
| AI / Machine-Learning | 0–100 (dynamic) | 65 | 85 |
| Coffee-Enhanced | 0–130 | 60 | 90 |
Each of these models appears in detail below, starting with the simplest and moving toward more data-hungry approaches.
Rule-Based Lead Scoring Model for Simple Pipelines
Rule-based models combine firmographic fit with behavioral signals and assign fixed point values to each criterion. Teams deploy this model quickly, and sales and marketing can audit it together without technical support.
| Criteria | Points | Fit / Intent | Negative Rules |
|---|---|---|---|
| Job title matches ICP (VP, Director, Head of) | +20 | Fit | −15 if individual contributor only |
| Company size 50–500 employees | +15 | Fit | −10 if <10 employees |
| Industry match (B2B SaaS) | +15 | Fit | −20 if excluded vertical |
| Demo request submitted | +30 | Intent | — |
| Pricing page visited | +20 | Intent | — |
| MQL threshold | 50 | — | SQL threshold: 75 |
Implementation note: This model fails when job title, company size, or activity fields are blank. Every criterion needs a populated CRM record to fire correctly. Recalibrate rule weights quarterly against closed-won data to prevent score drift.
Fit + Intent Lead Scoring Model for Balanced Qualification
This model separates fit and intent into two sub-scores so a highly engaged but poorly matched lead cannot reach SQL status. Each sub-score must clear a minimum threshold before the lead advances.
| Criteria | Points | Fit / Intent | Negative Rules |
|---|---|---|---|
| ICP title (economic buyer) | +25 | Fit | −10 if no budget authority |
| Tech stack includes target integration | +20 | Fit | — |
| Funding round in last 12 months | +15 | Fit | — |
| Webinar attended (full session) | +20 | Intent | −5 if attended >90 days ago |
| Case study or ROI content downloaded | +20 | Intent | — |
| MQL threshold | 55 combined; min 20 fit + 20 intent | — | SQL threshold: 85 |
Implementation note: Technographic and funding data should be enriched automatically. Manual enrichment creates lag, so the intent sub-score often goes stale before a rep sees it.
Enterprise / Account-Based Lead Scoring Model for Buying Committees
Account scoring aggregates fit, intent, and engagement signals across the entire buying committee, typically 6–10 stakeholders across executive leadership, procurement, IT, legal, and end users, instead of scoring a single contact. This multi-threaded approach matters because no single contact represents organizational intent in complex enterprise deals.
| Criteria | Points | Fit / Intent | Negative Rules |
|---|---|---|---|
| Account in ICP industry + size band | +30 | Fit | −20 if outside ICP |
| Economic buyer engaged (C-level or VP demo) | +35 | Intent | −15 if only junior contacts active |
| 3+ contacts from same account active in 30 days | +25 | Intent | — |
| Third-party intent data: competitor research detected | +30 | Intent | — |
| MQA Tier A threshold | 85+; routed to sales within 24 hours | — | Tier B: 60–84; Tier C: <59 |
Implementation note: A healthy MQA-to-opportunity conversion benchmark is 60–80%. Lower rates suggest marketing is passing false positives or sales is not adopting the model. Account-level scoring also depends on complete, correctly linked contact records.
Negative Scoring Model for Filtering False Positives
Negative scoring deducts points for disqualification indicators including personal email addresses, job-hopping patterns, and email unsubscribes. Without these rules, high-activity but low-fit leads inflate scores and waste rep capacity.
| Criteria | Points | Fit / Intent | Negative Rules |
|---|---|---|---|
| Personal email domain (gmail, yahoo, etc.) | −25 | Negative | Block from MQL queue entirely |
| Email unsubscribe or spam report | −30 | Negative | Suppress from all sequences |
| Job title: student, intern, or consultant | −20 | Negative | — |
| No activity for 60+ days | −15 | Negative | Move to nurture, remove from SQL queue |
| Net MQL threshold | 50 after deductions | — | SQL threshold: 75 net |
Implementation note: Shadow-CRM spreadsheets and personal-email leads create most false positives in mid-market pipelines. When reps log activity outside the CRM, negative rules never fire and inflated scores persist. Automatic activity capture closes this gap.
Time-Decay Lead Scoring Model for Recency Weighting
Engagement recency shapes intent strength, so a pricing page visit from yesterday should count more than one from 90 days ago. Time-decay models apply automatic downward adjustments after defined inactivity windows.
| Criteria | Points | Fit / Intent | Negative Rules |
|---|---|---|---|
| Any qualifying action within last 7 days | Full value | Intent | — |
| Action 8–30 days ago | −25% of original value | Intent | — |
| Action 31–60 days ago | −50% of original value | Intent | — |
| No action for 61–90 days | −75% of original value | Intent | Move to long-term nurture |
| MQL threshold | 50 (decay-adjusted) | — | SQL threshold: 75 |
Implementation note: Time-decay logic needs a reliable “last activity” timestamp on every record. When activity is logged manually or inconsistently, decay calculations use stale or missing dates and scores stop matching real prospect behavior.
Predictive Lead Scoring Model for Data-Rich Teams
Predictive models use historical closed-won data to weight signals by their actual correlation with conversion. Predictive lead scoring applies AI and machine learning to historical closed-won data to identify patterns that correlate with conversion. In 2026, three additional signal types have become standard inputs.
| Criteria | Points | Fit / Intent | Negative Rules |
|---|---|---|---|
| Visitor identification match (named individual, ICP title) | +25 | Intent | −10 if non-ICP company |
| Call-transcript intent keyword detected (pricing, timeline, budget) | +30 | Intent | — |
| Automated enrichment confirms ICP firmographics | +20 | Fit | −15 if enrichment returns no match |
| Closed-won pattern match score ≥ 0.7 (ML output) | +25 | Fit + Intent | — |
| MQL threshold | 60 | — | SQL threshold: 80 |
Implementation note: Predictive lead scoring models are only as reliable as the underlying CRM hygiene; without consistent assignment and ownership practices, predictive models degrade quickly. Visitor identification and call-transcript signals require a pixel and recording integration that send structured data back into the CRM automatically.
AI / Machine-Learning Lead Scoring Model for Continuous Tuning
AI lead scoring models continuously learn from new CRM data on lead outcomes and refine scoring criteria dynamically. Rule-based systems need explicit human maintenance to adapt, while ML-based scoring now serves as a competitive baseline for many teams using generative AI in marketing and sales.
| Criteria | Points | Fit / Intent | Negative Rules |
|---|---|---|---|
| ML-weighted ICP fit score (dynamic) | 0–40 (model-assigned) | Fit | Score suppressed if <3 fit fields populated |
| Behavioral sequence match (ML pattern) | 0–35 (model-assigned) | Intent | — |
| Engagement velocity (actions per week, trending up) | +15 bonus | Intent | −10 if velocity declining |
| CRM data completeness score ≥ 80% | Model activates | Prerequisite | Model suppressed if <80% |
| MQL threshold | 65 | — | SQL threshold: 85 |
Implementation note: AI lead scoring requires a dedicated data cleaning phase to remove inconsistencies, duplicates, and errors before model training can improve prediction accuracy. Data quality, not algorithm sophistication, remains the biggest barrier to trust in predictive lead scoring models.
Coffee-Enhanced Lead Scoring Model for Always-Complete Data
This model layers Coffee’s automatic data capture and enrichment on top of any rule-based or predictive framework above. Coffee auto-creates contacts from emails and calendars, enriches firmographics via licensed data partners, logs every activity autonomously, and surfaces named website visitors with ICP-matched suggested leads so every scoring criterion fires on complete, current data.

| Criteria | Points | Fit / Intent | Negative Rules |
|---|---|---|---|
| Coffee Visitor ID: named ICP visitor identified on site | +30 | Intent | −10 if non-ICP company detected |
| Coffee auto-enrichment confirms ICP title + company size | +25 | Fit | −15 if enrichment returns mismatch |
| Coffee call-transcript: BANT keyword cluster detected | +30 | Intent | — |
| Coffee activity log: 3+ touches in last 14 days (auto-captured) | +25 | Intent | −20 if last activity >45 days (auto-flagged) |
| MQL threshold | 60 | — | SQL threshold: 90 |
Implementation note: Coffee deploys as either a standalone CRM or a Companion App on top of existing Salesforce or HubSpot instances. In both setups, the agent writes enriched, structured data back to the system of record continuously so scoring rules fire on complete fields, time-decay timestamps stay accurate, and negative rules catch personal-email leads before they inflate pipeline.

The Impact of CRM Data Quality on Scoring Accuracy
The quality of lead scores depends entirely on the data that feeds them. Incomplete records cause rule-based models to skip criteria silently, time-decay models to calculate from wrong timestamps, and ML models to train on biased samples.
High-scoring leads in B2B SaaS often convert at much higher rates than low-scoring ones, but that gap appears only when scores reflect reality. When CRM fields are blank or stale, a lead that should score high may score low and never reach a rep.
Three data quality failures account for the majority of scoring drift in mid-market teams. Each one blocks a different type of scoring rule from working correctly:
- Personal-email leads: Negative scoring rules never fire if the email domain field is blank or populated from a shadow-CRM import, so low-quality leads inflate your MQL count.
- Stale activity timestamps: When reps log calls in personal notes rather than the CRM, “last activity” fields go weeks without updates and time-decay rules penalize active prospects based on outdated dates.
- Missing firmographic enrichment: Fit criteria cannot score what is not there, so incomplete records skip fit-based rules and may qualify on intent signals alone. Salesforce Einstein Lead Scoring accuracy depends entirely on the quality and completeness of CRM data; teams with inconsistent field usage or poor lead-to-opportunity attribution often find the scores unreliable.
How to Choose and Implement the Right Model
Model selection should match both your lead volume and deal complexity. Start with a simple framework and add layers as your pipeline and data mature.
- Under 200 leads/month, single decision-maker deals: Start with the Rule-Based or Fit + Intent model, which are easy to audit and run on limited data. Mid-market teams should start with a simple, manual process using a few high-signal inputs before gradually automating rules.
- 200–1,000 leads/month, 3–5 stakeholder deals: Once the base model is stable, add Negative Scoring and Time-Decay layers to filter out false positives and keep scores current.
- ABM motion, 6+ stakeholder accounts: When deals involve buying committees, shift to the Enterprise / Account-Based model with MQA thresholds and account-level routing.
- Sufficient closed-won history (500+ records): After you have enough conversion data, layer in Predictive or AI/ML scoring. Identify data gaps in behavioral, demographic, and firmographic data before training AI models, because AI thrives on complete and diverse data.
Clean CRM data is the prerequisite for every tier. A simple rule-based model running on complete records will often outperform a sophisticated ML model running on incomplete ones.
Conclusion: Lead Scoring Works Only on Reliable Data
Every model in this guide, including rule-based, fit + intent, enterprise ABM, negative scoring, time-decay, predictive, and AI/ML, works as designed only when the CRM data feeding it is complete, current, and automatically captured. The scoring logic is not the hard part. The hard part is enriching job titles, keeping activity timestamps accurate, flagging personal-email leads, and structuring call-transcript signals before any rule or model evaluates them.
Coffee’s agent handles that prerequisite continuously. It auto-creates and enriches contacts, logs every interaction from email and calendar, joins calls to extract BANT signals from transcripts, and identifies named website visitors, then writes all of it back to Salesforce, HubSpot, or its own CRM without manual input. The result is a system of record that scoring models can trust.
Frequently Asked Questions
What is the difference between a lead scoring model and account scoring?
Lead scoring evaluates an individual contact based on their firmographic fit and behavioral signals to determine whether they qualify as an MQL or SQL. Account scoring aggregates those individual signals, plus account-level intent data such as third-party research activity and buying committee engagement, across all contacts within a target account. Account scoring suits enterprise or ABM motions where six or more stakeholders influence a purchase decision, because a single highly engaged contact rarely represents organizational intent. Mid-market teams with shorter sales cycles and fewer decision-makers usually start with lead scoring and add account-level aggregation as deal complexity grows.
How many points should a demo request be worth in a B2B lead scoring model?
A demo request is one of the highest-intent signals available and is commonly worth between 25 and 35 points in a 0–100 scale model. The exact value depends on how it compares to other intent signals in your model and what conversion data from closed-won deals shows. If demo requests consistently appear in the histories of converted accounts, weight them near the top of your intent range. In a fit + intent split, a demo request should usually satisfy the intent sub-score minimum on its own, as long as the fit sub-score is also met before routing to sales.
How often should a lead scoring model be recalibrated?
A quarterly recalibration cycle works well for most mid-market B2B teams. Each recalibration should compare the criteria and point values of leads that converted to closed-won against those that stalled or churned. If the highest-scoring leads are not converting at a meaningfully higher rate than mid-tier leads, either the criteria weights are misaligned or the underlying CRM data is incomplete. Teams running AI or predictive models should also audit data completeness at each recalibration, because model accuracy degrades when new records lack the fields the model was trained on. Weekly or bi-weekly sales and marketing alignment reviews help catch threshold drift between formal quarterly recalibrations.
What negative scoring rules have the biggest impact on pipeline quality?
Personal email domain penalties and inactivity decay rules usually have the largest impact on removing false positives from the pipeline. Personal email addresses such as gmail, yahoo, or hotmail indicate a low probability of a business purchase and should trigger a significant point deduction or block the lead from the MQL queue entirely. Inactivity rules that deduct points after 30, 60, and 90 days of no engagement prevent stale leads from holding SQL status indefinitely and consuming rep capacity. Email unsubscribes and spam reports should trigger immediate suppression from all sequences, regardless of the lead’s current score. Job title mismatches, such as students or interns, are also worth penalizing explicitly rather than relying only on positive fit criteria to filter them out.
Can lead scoring work without a dedicated marketing automation platform?
Lead scoring can work without a dedicated marketing automation platform, but the model must stay simpler and data capture must stay disciplined. Teams without a full marketing automation stack can implement rule-based scoring directly in their CRM using custom fields and workflow automation, as long as contact records remain complete and activity is logged consistently. The main risk is that behavioral signals such as page visits, content downloads, and email engagement are harder to capture without a marketing automation layer feeding the CRM. An agent that automatically logs interactions from email, calendar, and call transcripts provides much of that behavioral data layer without requiring a separate platform investment.


