Written by: Doug Camplejohn, CEO & Co-Founder, Coffee
Key Takeaways
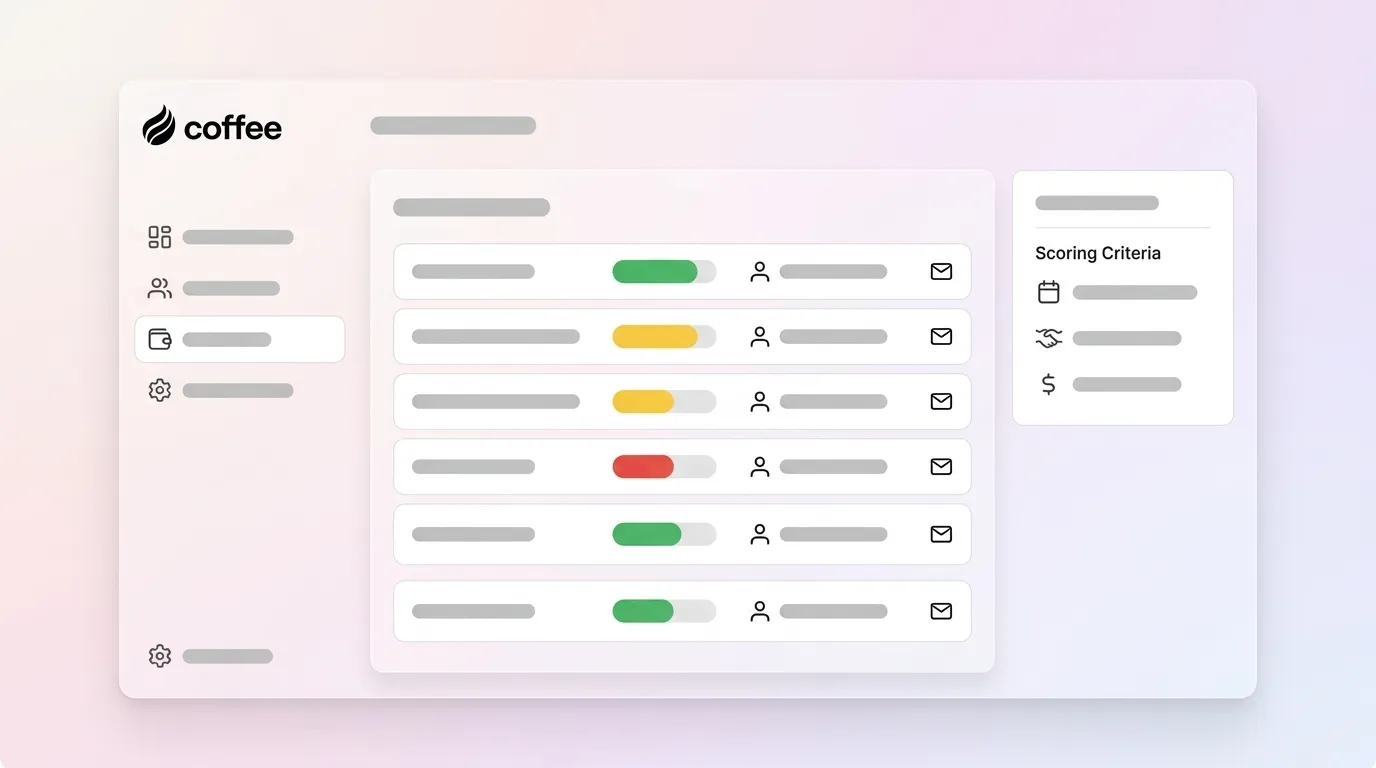
- Deal scoring criteria use activity levels, stakeholder engagement, stage velocity, deal size, and firmographic fit to rank pipeline opportunities by close likelihood.
- Accurate forecasts depend on clear scoring weights and clean, current CRM data, because missing or outdated inputs undermine any model.
- Effective models blend rule-based and predictive AI approaches, with weights calibrated quarterly against the last 100 closed-won deals.
- Stage-specific thresholds and decay scoring keep models actionable and prevent score inflation from stale records.
- An autonomous agent that continuously captures activity and enriches CRM fields is essential for maintaining scoring accuracy, so automate your CRM data capture with Coffee.
Executive Overview for 5–50 Seat SaaS Teams
For 5–50 seat SaaS teams, an inaccurate pipeline forecast creates real operational risk. It drives missed hiring decisions, misallocated marketing spend, and board conversations built on fiction. Deal scoring replaces gut-feel prioritization with a repeatable, auditable framework that makes those calls more reliable.
The catch is data quality. Unreliable CRM inputs, such as missing fields, outdated records, and inconsistent stage definitions, produce unreliable scoring outputs, regardless of whether the model is rule-based or AI-driven. Every framework below assumes clean, current data, and the later sections walk through how to maintain that standard without adding rep workload.
Deploy Coffee’s autonomous agent to keep your CRM data accurate from day one and give your scoring model a trustworthy foundation.
Core Deal Scoring Dimensions and Weights
Effective scoring models combine firmographic fit, behavioral signals, engagement quality, and timing signals, with weights derived from closed-won patterns rather than assumptions. The table below shows a practical starting allocation based on patterns common in mid-market SaaS. It favors near-term buying signals such as activity, stakeholder engagement, and stage velocity over static attributes, because engaged deals with decent fit close more reliably than perfect-fit accounts with no momentum. Weights should be reviewed quarterly against the last 100 closed-won deals.

| Dimension | Example Weight | Key Signals |
|---|---|---|
| Activity & Engagement | 25% | Emails replied, calls completed, meetings held |
| Stakeholder Involvement | 20% | Economic buyer engaged, champion identified, multiple contacts active |
| Stage Velocity | 20% | Days in current stage vs. benchmark, forward movement cadence |
| Firmographic Fit | 20% | Company size, industry, geography, tech stack |
| Deal Size & Timeline | 15% | ACV vs. target range, stated close date, budget confirmed |
High-readiness signals include budget confirmed with a specific range stated, a decision-maker actively engaged, urgent pain articulated, a timeline tied to a specific date or event, and an internal champion identified. Negative scoring for disqualification indicators such as personal email addresses, unsubscribes, or prolonged silence prevents score inflation over time.

Choosing Between Rule-Based and Predictive Scoring
Traditional rule-based systems stay static until someone updates them, while predictive AI models retrain on new data and adapt to changing patterns. The comparison below outlines implementation requirements and accuracy characteristics so your team can decide whether a predictive approach fits your data volume, skills, and accuracy needs, or whether a simpler rule-based model will deliver enough value with less overhead.
| Factor | Rule-Based | Predictive AI |
|---|---|---|
| Implementation Skills | SQL, Excel, BI tools | Python, ML, statistics |
| Accuracy Ceiling | 65–70% (rules-only) | Exceeds 99% in AI-native platforms |
| Maintenance Burden | Requires constant manual tuning | Retrains continuously on new data |
| 2026 Adoption Signal | Declining as baseline | 48% of B2B sales teams use AI for deal scoring |
Hybrid approaches that combine AI models with configurable business rules outperform either method alone. Predictive scoring uncovers patterns humans miss, such as repeated pricing page visits correlating with higher conversion rates, which a static rule set would not surface without prior analysis.
The Critical Role of CRM Data Quality
Predictive models only perform as well as their inputs. Sales teams should audit workflows for CRM update, qualification, and follow-up breakdowns before deploying any scoring automation. The audit should focus on three failure modes: incomplete field population, stale records that no longer reflect deal status, and weak activity capture that leaves engagement signals unlogged.
The root cause usually sits in the system design. Legacy CRMs rely on sales reps to enter data manually. AI lead scoring platforms require real-time CRM synchronization with bi-directional updates so that scores continuously reflect the most current data without manual intervention. Without that synchronization, a deal can sit at a high score for weeks after the champion leaves the account or the timeline slips, because no one updated the record.
Any automation step that fails a data-readiness check requires fixing upstream CRM hygiene or enrichment problems before the automation proceeds. Scoring is downstream of data. Fix the data first, then define the score ranges that trigger specific actions at each pipeline stage.
Stage-Specific Thresholds That Protect Rep Time
HubSpot’s lead scoring tool can be configured with custom score thresholds to categorize leads as high, medium, or low. Mapping those bands to pipeline stages produces routing rules that keep low-quality deals from advancing and consuming rep time. The thresholds below represent the minimum engagement and fit levels that typically allow deals to progress successfully at each stage, while deals below these scores tend to stall or require disproportionate effort. Treat them as starting points and calibrate against your own closed-won data after 60–90 days.
| Pipeline Stage | Minimum Score to Advance | Action if Below Threshold |
|---|---|---|
| Marketing Qualified Lead | ≥ 40 | Return to nurture |
| Sales Qualified Lead | ≥ 55 | Re-qualify or disqualify |
| Demo / Discovery | ≥ 60 | Flag for manager review |
| Proposal / Evaluation | ≥ 70 | Escalate or apply save play |
| Negotiation / Close | ≥ 80 | Executive sponsor outreach |
Build in decay scoring so that scores stay relevant over time rather than inflating permanently. A deal that has not had a logged activity in 14 days should lose points automatically, not hold its score from the last meeting.
HubSpot and Salesforce Setup Tips
HubSpot Sales Hub Professional and Enterprise users can create combined engagement and fit scores for deals, and when a score is turned on or updated, records are evaluated retroactively, after which the score property updates continuously. Key configuration steps include creating custom score properties for each dimension, setting workflow triggers that fire when a score crosses a threshold, and scheduling a recalculation cadence aligned to your average sales cycle length.
In Salesforce, Einstein Deal Insights or custom formula fields serve the same purpose. The configuration pattern stays the same across both platforms. Define the fields, weight them in a formula or flow, and trigger alerts or stage changes when thresholds are crossed.
The limiting factor in both platforms is field population. An agent layer that auto-captures emails, calls, and calendar events, then writes structured data back to the required CRM fields, removes the dependency on rep discipline entirely.
Common Pitfalls That Break Scoring Accuracy
The most common scoring failures fall into two groups, configuration errors and data decay. Configuration errors include static thresholds that never change, overfitting early models with too many variables, and mixing deal cohorts with inconsistent stage definitions. Data decay problems stem from rep-dependent updates and systems that lose history, which erode accuracy over time.
- Static thresholds: Scoring models must be revisited quarterly and recalibrated based on closed-won trends, because thresholds set at launch become stale as market conditions shift. The quarterly recalibration mentioned earlier prevents this drift.
- No historical context: Legacy CRM architectures lose historical field values when records are updated, which makes it impossible to detect velocity changes or score decay accurately.
- Rep-dependent updates: Treat AI lead scoring as an ongoing operating discipline rather than a one-time setup, because inputs drift, rep behavior changes, and market conditions evolve. Any model that relies on manual entry will degrade.
- Overfitting early models: Keep the first model simple, using only a few high-signal inputs such as job title, company size, industry, and three to five key behaviors.
- Mixing deal cohorts: Common mistakes in pipeline analysis include mixing deals at different lifecycle stages and allowing inconsistent stage definitions or subjective assignments.
Automation Best Practices for Reliable Scores
Maintaining clean CRM data through automated deduplication, third-party enrichment to fill information gaps, and standardization of formats is required for accurate ongoing AI scoring predictions. An always-on agent can handle these tasks by capturing emails, calls, and calendar events, enriching contact and company records, and logging activities to the deal record without waiting for a rep.
Automation delivers the highest ROI with lowest risk when applied to behind-the-scenes GTM steps such as data enrichment, lead scoring, and routing rather than buyer-facing interactions. That focus on back-end processes is exactly where Coffee operates.
Coffee’s autonomous agent connects to Google Workspace or Microsoft 365 and immediately begins logging activity, enriching records, and writing structured data back to HubSpot or Salesforce. Every email thread, call transcript, and calendar event becomes a scored input automatically. Deal scores reflect reality because the data feeding them reflects reality. AI-driven lead scoring can reduce sales costs by 40% when the data foundation is sound, and Coffee keeps that foundation stable.
Let Coffee handle the data entry that quietly breaks scoring models over time.
Frequently Asked Questions
How do I choose between a rule-based and a predictive deal scoring model?
Start with a rule-based model if your team has fewer than 50 closed deals in the CRM, because predictive models need sufficient historical data to identify reliable patterns. Once you have 100 or more closed-won and closed-lost records with consistent field population, a predictive or hybrid approach will outperform static rules. Most modern CRM platforms, including HubSpot and Salesforce, now offer built-in predictive scoring that does not require a data science team to configure.
What is a good deal score threshold by stage?
There is no universal answer, but a practical starting framework maps thresholds to pipeline progression gates: MQL at 40+, SQL at 55+, Demo at 60+, Proposal at 70+, and Negotiation at 80+. Treat these numbers as hypotheses, not fixed rules. After 60–90 days, compare the scores of deals that closed won versus closed lost at each stage and adjust thresholds to match the actual distribution in your pipeline.
What data sources should feed a deal scoring model?
The most reliable inputs are email engagement such as replies and response time, meeting activity such as calls held, attendees, and recency, CRM field completeness such as budget confirmed, decision-maker identified, and close date set, firmographic fit such as company size, industry, and tech stack, and behavioral signals such as pricing page visits, content downloads, and demo requests. These fields must be populated automatically rather than manually. Any field that depends on a rep remembering to update it will develop gaps that degrade scoring accuracy over time.
How does Coffee integrate with HubSpot or Salesforce?
Coffee deploys as a Companion App on top of existing HubSpot or Salesforce instances. A simple authentication allows the Coffee Agent to sync data bidirectionally. It reads existing records, enriches them with contact and company data from licensed partners, captures activity from connected email and calendar accounts, and writes structured outputs such as call summaries, next steps, and updated field values back to the CRM. No complex implementation is required, and the agent begins populating fields immediately after connection.
Is Coffee secure enough for sales data?
Coffee is SOC 2 Type 2 and GDPR compliant. Customer data is not used to train public models. For teams in heavily regulated industries such as healthcare or finance that require multi-year security reviews or custom compliance frameworks, Coffee recommends evaluating whether those requirements fall outside the standard compliance posture before proceeding.
Conclusion: Make Scoring Reliable with Better Data
Deal scoring criteria provide the structural foundation for accurate pipeline forecasting. The framework stays simple in concept. Define weighted dimensions, set stage-specific thresholds, choose the right model type for your data volume, and review quarterly. The execution challenge sits in data quality, because every scoring model described above degrades when CRM fields are stale, incomplete, or manually maintained.
An autonomous agent that captures activity, enriches records, and logs interactions continuously is not a nice-to-have addition to a scoring framework. It is the prerequisite that makes the framework reliable. Coffee fills that role as a standalone CRM or as the data layer running on top of your existing HubSpot or Salesforce instance.
Start your free Coffee trial and build a scoring model that stays accurate without adding a single manual step to your team’s workflow.


