Written by: Doug Camplejohn, CEO & Co-Founder, Coffee
Key Takeaways
- Legacy CRMs rely on inconsistent manual data entry, which causes missed forecasts and significant, recurring revenue loss.
- AI-driven agents remove human data-entry errors by capturing and structuring information automatically from emails, calendars, and meetings.
- Automated CRM systems deliver measurable gains, including 40% less manual work, 31% faster deal closures, and 29% higher sales revenue.
- Coffee works as both a standalone AI-first CRM and a companion layer for Salesforce or HubSpot, keeping records accurate without rep effort.
- Teams ready to replace manual CRM work with reliable pipeline intelligence can see Coffee’s pricing and start a trial.
The Problem: Manual CRM Entry Breaks Forecasts
Sales teams rely on CRM data to run pipeline reviews, build forecasts, and allocate resources, yet the data inside most CRMs is structurally unreliable. Fewer than 50% of sales leaders have high confidence in their forecasts, with poor CRM and pipeline data quality cited as the primary driver of that distrust. 79% of sales organizations miss their forecast by more than 10%, and 45% of forecasted deals slip to later quarters due in part to inaccurate or outdated CRM records.
These misses are not just planning errors; they translate directly into lost revenue and wasted headcount. The financial consequences are measurable and severe. Poor data quality costs companies a significant portion of revenue by producing unreliable forecasts built on inaccurate CRM inputs. A Validity survey found that 44% of companies lose more than 10% of annual revenue due to low-quality CRM data, and IBM research estimates bad data costs the U.S. economy approximately $3.1 trillion annually.
The core issue starts with architecture. Legacy CRMs behave like passive databases that require humans to act as data-entry clerks. Human error from typographical mistakes, missed required fields, fatigue, and inadequate training significantly degrades accuracy when information is entered manually. Reps engage in selective logging, omitting calls that went poorly, writing notes hours or days later, and leaving fields inconsistent across the team. B2B contact data degrades at roughly 2.1% per month, which produces more than 22% annual decay without automated maintenance. Missing deal information, incorrect stage classifications, and stale contact data distort pipeline visibility and make accurate forecasting impossible.
Over time, the CRM turns into a repository of opinions rather than facts. Most sales teams have data scattered across CRM systems, email platforms, call recording tools, marketing automation platforms, and spreadsheets, making real analysis nearly impossible. When the system of record cannot be trusted, shadow CRMs in spreadsheets and Notion become the real workspace, which fragments the data that forecasts depend on even further.
These architectural differences explain why passive databases cannot deliver the data quality that modern forecasting requires. The table below highlights five core capabilities where agent-driven systems remove the manual bottlenecks that cause data decay in legacy CRMs.
| Capability | Passive Database (Legacy CRM) | Agent-Driven System (Coffee) |
|---|---|---|
| Data entry method | Manual, rep-dependent | Autonomous capture from email, calendar, and meetings |
| Unstructured data handling | Not supported, relational fields only | Ingests and structures email text, call transcripts, and summaries |
| Historical context retention | No version history when fields change | Preserved in a built-in data warehouse |
| Contact data decay | Annual decay above 22% without intervention | Continuously enriched via licensed data partners |
| Forecast reliability | Low, built on partial and lagged data | High, built on complete, real-time activity data |
AI-Driven CRM Agents That Capture Data at the Source
Fixing CRM data quality at scale requires removing the human data-entry step entirely. AI agents in CRM can orchestrate processes across sales, marketing, and service, triggering actions and automating data entry without manual intervention. Instead of cleaning bad data after it enters the system, agent-driven architectures prevent bad data from forming by capturing and structuring information at the point of interaction.
The operational benefits show up quickly on the calendar. AI automation in CRM systems cuts manual data work by 40%, reclaiming an average of four hours per week per rep. Mixmax customers save over two hours per rep per day by eliminating manual CRM updates, then redirect that time to selling. Sales teams lose substantial selling time each week when they rely on manual CRM logging.
Automated capture also creates structurally superior data. Automated logging creates a reliable, real-time source of truth that enables accurate forecasting and coaching. It replaces rep self-reports with an objective record of every conversation. AI-powered CRM automation helps businesses close deals 31% faster on average, and sales teams using CRM generate 29% higher sales revenue on average by enabling targeted outreach based on real buying signals.
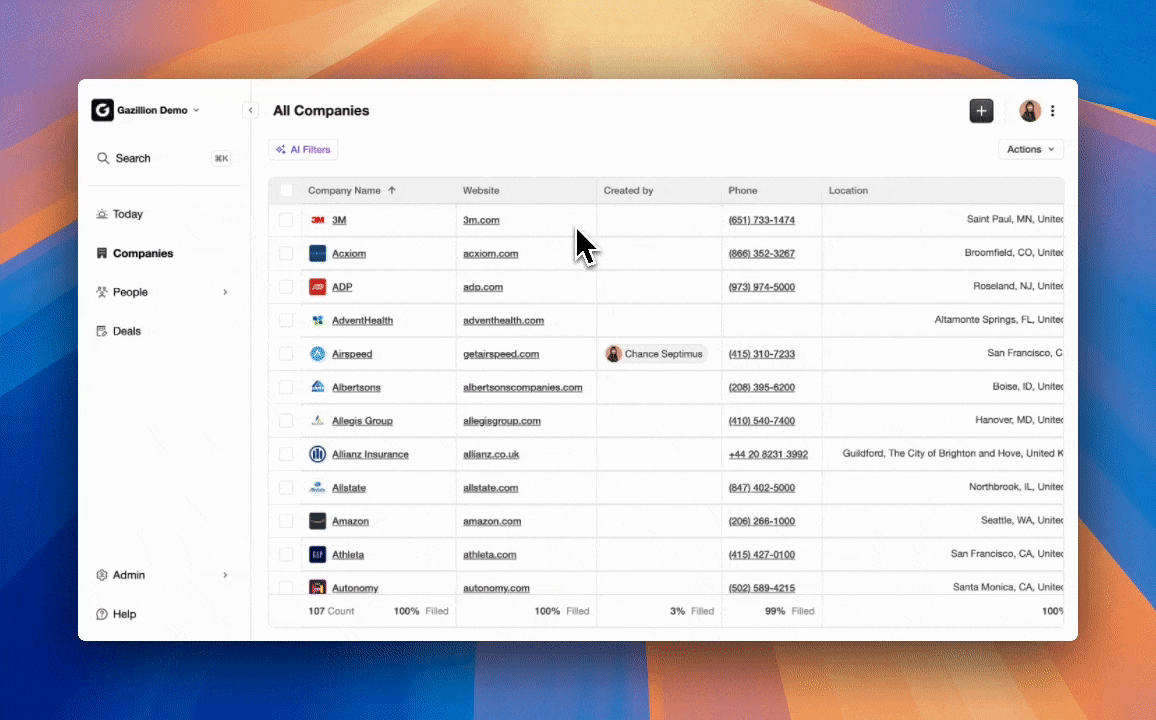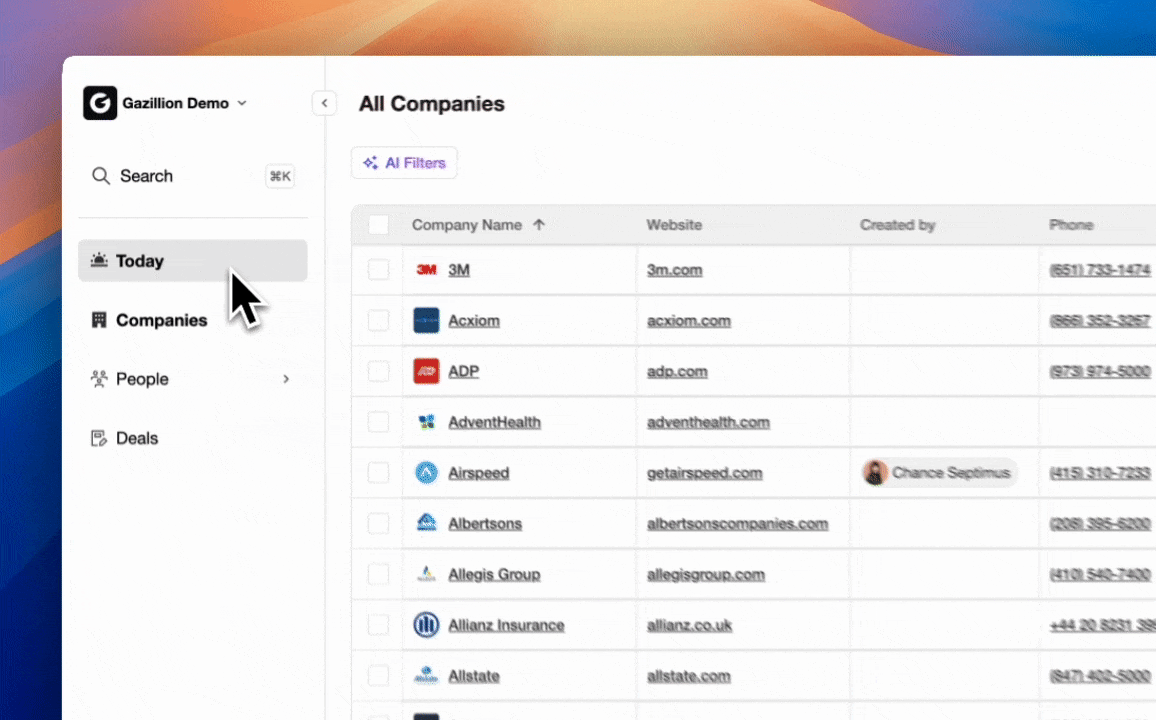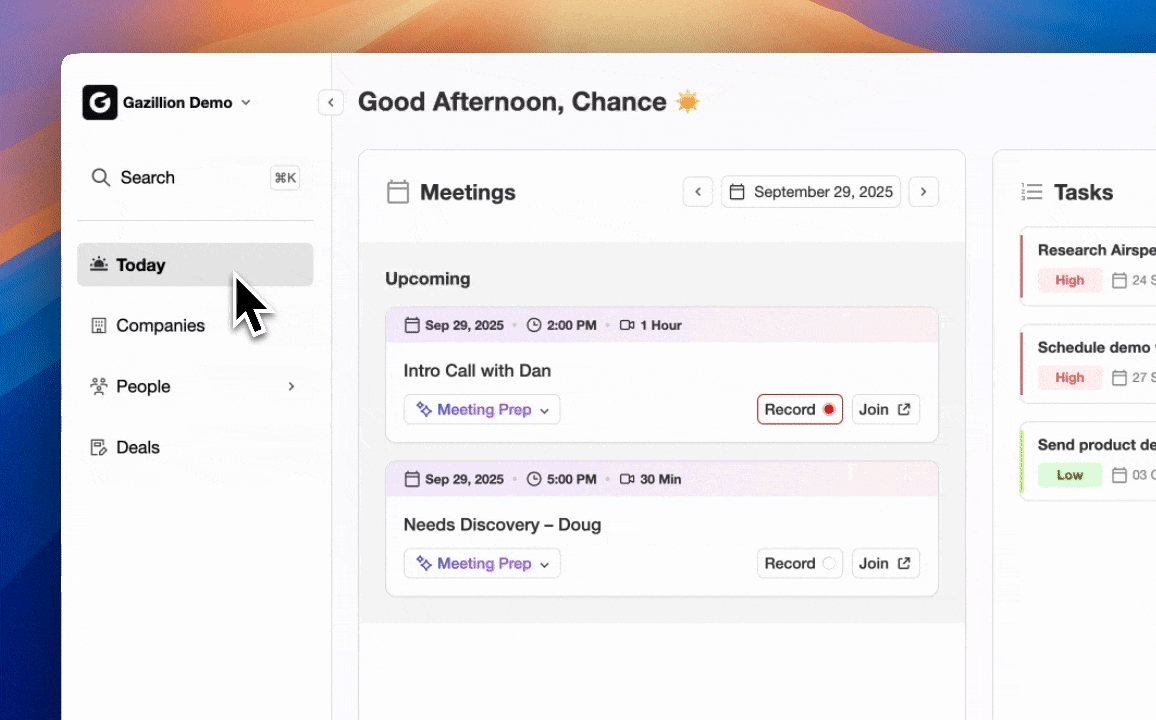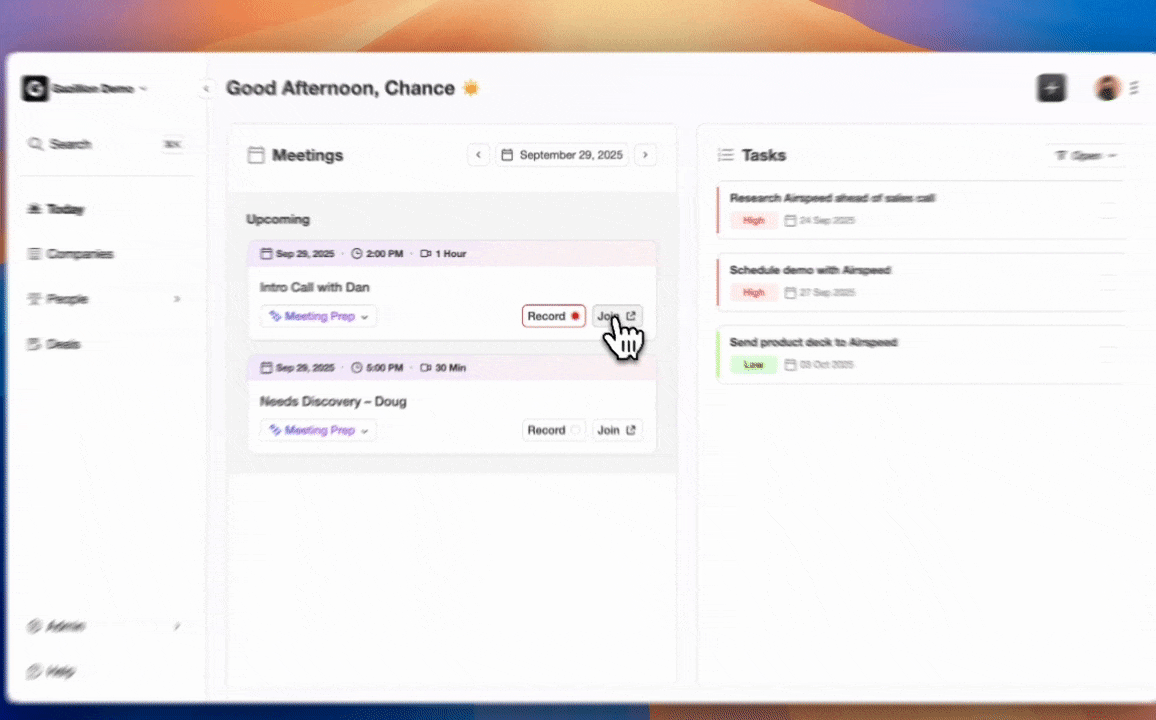
The end-to-end flow of an agent-driven CRM starts at authentication and then runs continuously in the background. After connection to Google Workspace or Microsoft 365, the agent scans emails and calendars to auto-create contacts and companies, then associates every note and interaction with the correct record. It augments those records with job titles, funding data, and LinkedIn profiles via licensed enrichment partners. Activity logging for last contact, next scheduled touchpoint, and deal stage updates in real time without rep input. When a meeting occurs, the agent joins the call, records and transcribes it, generates a structured summary aligned to BANT, MEDDIC, or SPICED, and drafts follow-up emails for rep review. Pipeline changes appear automatically week over week, which turns pipeline reviews from interrogation sessions into strategic discussions.

Eliminate manual data entry and get clean pipeline data. View Coffee’s plans and start a trial.
How Coffee Improves CRM Data Accuracy in Practice
Coffee operates in two distinct modes so teams can match the product to their current stack. It works as a standalone AI-first CRM for teams of 1–20 and as a companion layer deployed on top of existing Salesforce or HubSpot instances for small-to-mid-market teams. In both modes, the Coffee Agent handles the data-in process autonomously and keeps the system of record accurate without human effort.
McKinsey research on AI in marketing and sales highlights gains such as more leads, lower costs, and shorter call times. Organizations implementing AI-driven forecasting solutions can reduce forecast errors by 30–50% by replacing subjective human inputs with objective analysis. Teams that improve CRM data hygiene see forecast accuracy rise as a direct result.
Not every automation approach delivers the same data quality, so the underlying mechanism matters as much as the intent. The table below isolates five technical capabilities that determine whether a CRM prevents bad data from forming or simply validates it after entry. Use this comparison to judge whether your current system addresses root causes or only adds friction to a broken process.
| Mechanism | Manual Entry | Validation Rules | Agent Automation (Coffee) |
|---|---|---|---|
| Data capture trigger | Rep action required | Rep action required | Autonomous, no rep action needed |
| Unstructured data (emails, transcripts) | Not captured | Not captured | Ingested and structured automatically |
| Duplicate detection | Manual, prone to duplication errors | Rule-based, limited to exact matches | AI-driven across naming variations |
| Enrichment | Requires separate tool (ZoomInfo, Apollo) | Not included | Built-in via licensed partners |
| Historical context | Discarded on update | No persistent history | Preserved in data warehouse |
Teams evaluating CRM solutions for data accuracy can use the checklist below to avoid common pitfalls and confirm that a platform will hold up over time.
- Integration depth: Does the system write enriched data back to Salesforce or HubSpot automatically, or does it require manual export? If enrichment lives in a separate tool that depends on CSV exports, you add another manual step that will decay over time. Coffee’s companion mode authenticates once and syncs bidirectionally so your system of record stays current without export workflows.
- Unstructured data handling: Even with strong integration, a CRM that only accepts structured fields will miss most of your sales intelligence. Only 3% of enterprise data meets basic quality standards partly because legacy systems cannot process email text or call transcripts, which contain the real buying signals. Confirm the CRM ingests and structures both.
- Security compliance: Automation that sends your data to third-party AI APIs introduces compliance risk that many teams cannot accept. Coffee is SOC 2 Type 2 and GDPR compliant, and customer data is not used to train public models. Verify equivalent certifications from any alternative before connecting your email and calendar.
- Implementation effort: Long implementations delay value and reduce adoption. Coffee activates upon Google Workspace or Microsoft 365 authentication, so teams avoid multi-month deployment projects.
- Team size fit: A CRM designed for a different scale often creates either bloat or constraints. Coffee’s standalone CRM serves teams of 1–20, while the companion app serves small-to-mid-market teams already on Salesforce or HubSpot. Confirm the vendor’s ICP matches your current and near-term size.
- Enrichment match rate: Weak enrichment leaves gaps that reps must fill manually. Waterfall enrichment querying multiple data providers achieves 85%+ match rates, compared to 40–65% from single providers. Coffee uses licensed multi-source enrichment by default to keep profiles complete.
Frequently Asked Questions
What is CRM data accuracy and why does it matter for sales forecasting?
CRM data accuracy describes how closely records in a CRM system match the real state of contacts, companies, deals, and activities. When accuracy is low because of missing fields, stale contacts, or selective logging, pipeline reviews and forecasts are built on fiction. As noted earlier, this trust gap affects the majority of sales organizations, with data quality consistently identified as the root cause. Accurate CRM data supports reliable forecasting, targeted outreach, and evidence-based coaching.
Can Coffee work alongside my existing Salesforce or HubSpot instance?
Yes. Coffee operates as a companion app that deploys the Coffee Agent as an intelligent layer on top of an existing Salesforce or HubSpot installation. A single authentication allows the agent to read activity data, enrich records, and write structured insights back to the primary CRM. Teams keep their existing system of record while the agent takes over the data-entry work that reps currently perform manually.
What data sources does the Coffee Agent capture from?
The Coffee Agent connects to Google Workspace or Microsoft 365 and immediately begins scanning emails and calendars to auto-create contacts, companies, and activity logs. It joins calls on Zoom, Google Meet, and Microsoft Teams to record, transcribe, and summarize meetings. It enriches records with job titles, funding data, and LinkedIn profiles via licensed data partners. It also identifies anonymous website visitors and infers their name, title, email, and company from a single tracking pixel.

Is Coffee secure, and how is my data handled?
Coffee is SOC 2 Type 2 and GDPR compliant. Customer data is not used to train public AI models. The platform uses seat-based pricing with no complex metering on AI usage, and security certifications are maintained continuously rather than treated as a one-time audit.
How quickly can a team expect to see improvements in data quality after adopting Coffee?
Teams see improvements in data quality from day one because the Coffee Agent begins capturing and structuring data immediately after authentication. Reps do not need to change behavior for contacts and companies to be created automatically from existing email and calendar history. Activity logs populate in real time. Pipeline change visualization becomes available as soon as the agent has enough deal history to compare. Teams typically reclaim 8–12 hours per rep per week that were previously spent on manual data entry and administrative tasks.
Conclusion: Why Agent-Led CRMs Win on Data Accuracy
Legacy CRMs fail at their core function because they depend on humans to maintain data quality, and humans are unreliable data-entry clerks under sales pressure. The result is incomplete records, stale contacts, missed activities, and forecasts that miss by double digits. The only architecture that solves this at the root uses an autonomous agent that captures, structures, and enriches data without requiring rep action.
Coffee provides that agent-driven architecture. It works as a standalone CRM for growing teams and as a companion layer for organizations already committed to Salesforce or HubSpot. In both modes, it removes the manual entry burden, preserves historical context, processes unstructured data from emails and call transcripts, and delivers pipeline intelligence that reflects what is actually happening in the field, not just what reps chose to log.
Stop managing a database. Start running a pipeline. See Coffee’s pricing and start your trial.