Written by: Doug Camplejohn, CEO & Co-Founder, Coffee
Key Takeaways
- Stale CRM data from manual entry is the root cause of unreliable deal scores and missed forecasts, costing companies 10–30% of revenue annually.
- Deal scoring improves pipeline visibility by turning activity velocity, engagement depth, stage progression, historical patterns, and risk signals into ranked, actionable views.
- Traditional CRMs fall short because manual entry introduces errors, loses unstructured context, and leaves 60–73% of data unused for analytics.
- AI agents fix the problem at the source by autonomously capturing, enriching, and structuring data from email, calendar, and transcripts to deliver live, trustworthy scores.
- Teams ready to eliminate manual data entry can explore Coffee’s pricing and plans to unlock accurate, real-time pipeline visibility.
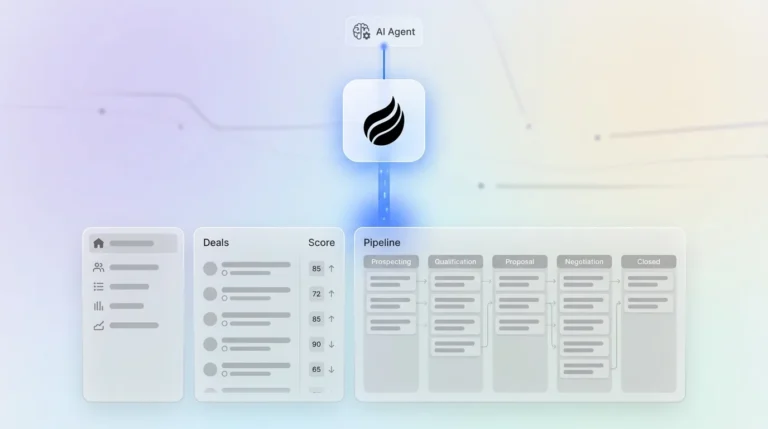
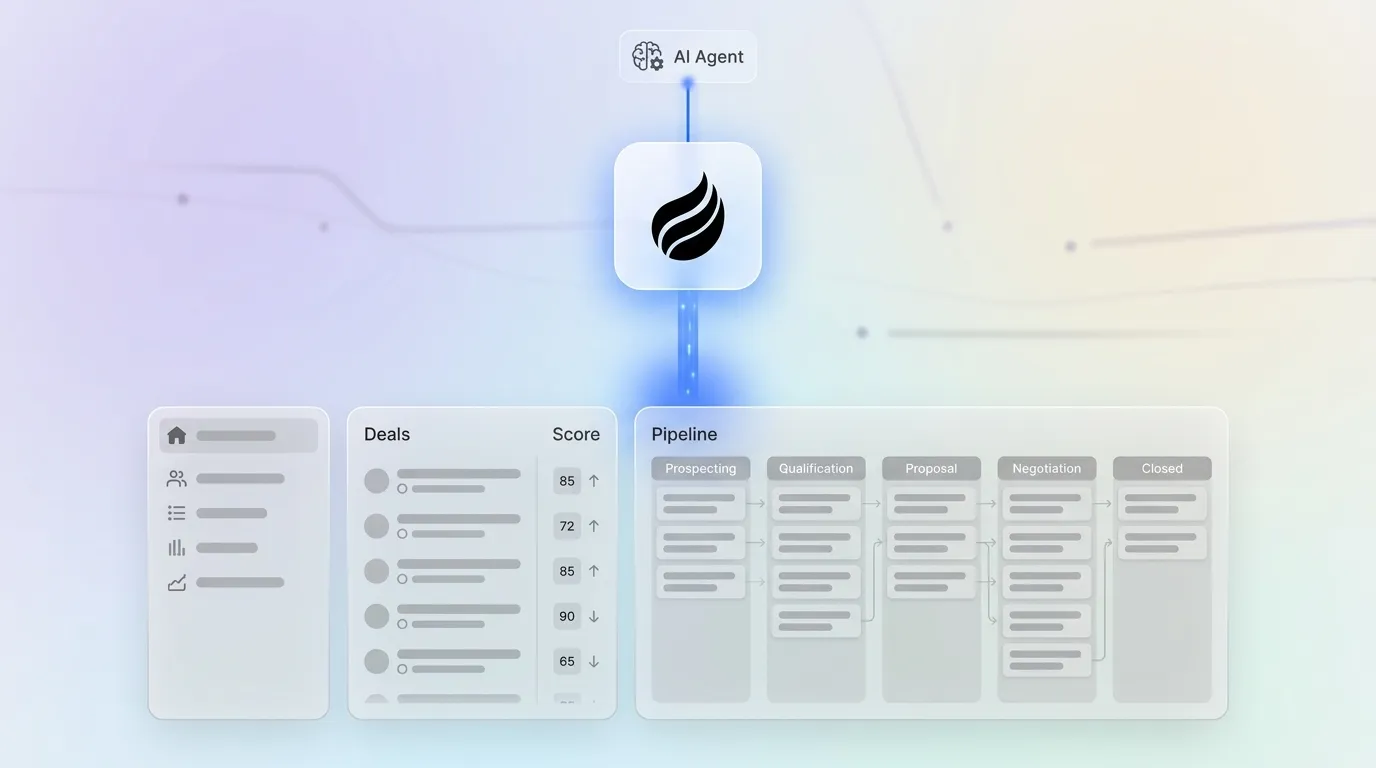
How Deal Scores and Pipeline Visibility Work Together
A deal score is a numeric or tiered rating assigned to an open sales opportunity that reflects its likelihood of closing. The score draws on weighted signals from activity, engagement, firmographic fit, stage progression, and historical win patterns. Pipeline visibility is the real-time, accurate view of every scored opportunity across stages. This view lets sales leaders forecast revenue, spot risk, and prioritize rep effort without chasing manual status updates.
How Deal Scoring Turns Raw Activity Into Clear Pipeline Views
Deal scoring converts raw CRM activity into a ranked pipeline view that shows which opportunities deserve attention first. Five categories of data determine scoring quality, and each one captures a different dimension of deal health.
- Activity velocity, which tracks how often and how recently interactions occur, including emails sent, calls completed, and meetings held.
- Engagement depth, which reflects the quality of buyer responses such as reply rates, content downloads, demo attendance, and pricing page visits.
- Stage progression, which measures how quickly and consistently deals move through defined stages compared with historical win patterns.
- Historical win patterns, which link firmographic and behavioral attributes to closed-won deals in the CRM’s training data.
- Risk signals, which highlight stagnation indicators like days without activity, missed follow-ups, and stakeholder disengagement.
Deals stalled beyond 28 days show 67% lower conversion rates (14.3% vs. 43.2%). That drop makes activity velocity and risk signal detection the most powerful inputs for improving pipeline visibility.
Core Inputs That Feed a Deal Scoring Model
Effective B2B scoring models combine account fit, intent data, and engagement data into a unified score that ranks opportunities by conversion likelihood. Each input category plays a specific role in that ranking.
Firmographic and ICP fit signals measure alignment with the ideal customer profile using industry, company size, annual revenue, geography, and technology stack. Firmographic signals are correlated with past successful deals to predict conversion likelihood.

Behavioral signals track how frequently a contact visits product-related pages, downloads content, attends webinars, or interacts with sales emails. AI scoring models analyze every page view, download, and form submission to build lead profiles.
Engagement signals capture the depth of direct brand interaction, including pricing page visits, demo requests, case study downloads, email click-throughs, and sales conversation frequency. Modern scoring models assign explicit point values to these attributes, for example: pricing page visit = 30 points, researching competitor names = 20 points.
Intent signals include both first-party data such as website visits and form fills and third-party signals such as searches for relevant topics or activity on analyst and review sites. These signals show whether an account is actively in-market.
Negative signals apply score deductions for disengagement, personal email addresses in B2B contexts, incomplete records, or prolonged stage stagnation. These deductions sharpen the final conversion probability estimate.
Because AI scoring models synthesize firmographic, behavioral, engagement, intent, and negative signals, sales teams can focus time on the opportunities most likely to convert. Reps spend more hours with qualified leads and fewer on dead-end prospects.
Why Traditional CRMs Struggle With Accurate Scoring
Legacy CRM architectures were built to store data entered by humans, not to capture it autonomously. That design creates three structural failure modes that undermine scoring reliability. The benefits of AI scoring depend on data quality, and this is where traditional CRMs start to break down.
Manual entry error rates compound at scale. Even with a baseline accuracy of 96%, a sales team logging 1,000 records per month introduces about 40 errors. Those errors accumulate across quarters and corrupt the historical data that scoring models use to identify win patterns.
Unstructured data is lost. Legacy relational databases cannot ingest email text, call transcripts, or meeting notes in a way that preserves context. When fields are updated, historical context disappears and cannot be recovered later.
Data goes unused. Forrester reports that 60–73% of enterprise data goes unused for analytics. Valuable signals never reach the scoring model.
| Dimension | Manual CRM Entry | Agent-Automated Capture | Impact on Scoring |
|---|---|---|---|
| Data entry accuracy | Approximately 96% average accuracy for manual CRM data entry (4.1% error rate) | 95%+ accuracy in automated extraction | Higher accuracy produces more reliable score inputs |
| Record completeness | 76% of organizations report that less than half of their CRM data is accurate and complete | Automated ingestion from email, calendar, and transcripts fills gaps continuously | Complete records eliminate missing-field scoring gaps |
| Forecast accuracy range | 65–75% forecast accuracy with manual/rep roll-up CRM methods | Vendors claim 90–97% accuracy for AI revenue forecasting, while actual median B2B forecast accuracy is 70–79%. | Automated data capture is a prerequisite for AI-level forecast accuracy |
| Rep time on data entry | 20–30% of the work week | Reduced to near zero with autonomous logging | Frees rep time for selling and reduces data lag in pipeline views |
Eliminate manual data entry from your pipeline and see Coffee’s autonomous capture in action by visiting the pricing page.
Improving Pipeline Visibility Without Manual Data Entry
AI-driven CRM agents solve the data quality problem at the source by replacing human data entry with autonomous capture, enrichment, and structured logging. The agent ingests raw signals from email, calendar, and call transcripts. It enriches records with firmographic and technographic data, writes structured logs to the CRM, calculates deal scores from clean inputs, and surfaces live pipeline dashboards that reflect current deal state.
Real-Time Activity Capture That Keeps Scores Fresh
An agent connected to Google Workspace or Microsoft 365 logs every email, meeting, and call automatically. Activity velocity, one of the five core scoring inputs, stays current without rep effort. AI automates CRM updates by transcribing call recordings, extracting key information to appropriate fields, logging email interactions, updating deal stages based on detected signals, and creating follow-up tasks automatically.
Automated Risk and Stagnation Alerts for At-Risk Deals
AI sales forecasting software uses machine learning algorithms to adjust predictions in real time as new pipeline data, customer behavior, and market conditions change, unlike traditional tools that rely on static historical data and spreadsheets. Agents use the same live data to flag stalled deals, missed follow-ups, and disengaged stakeholders before they slip from the forecast.
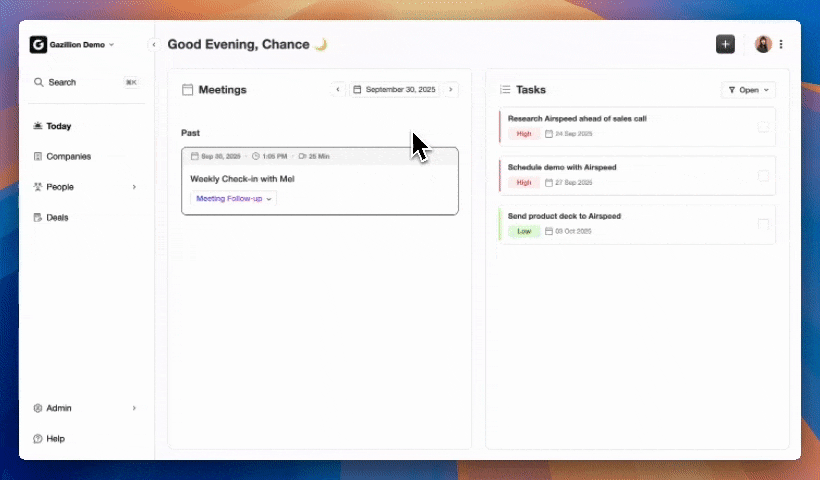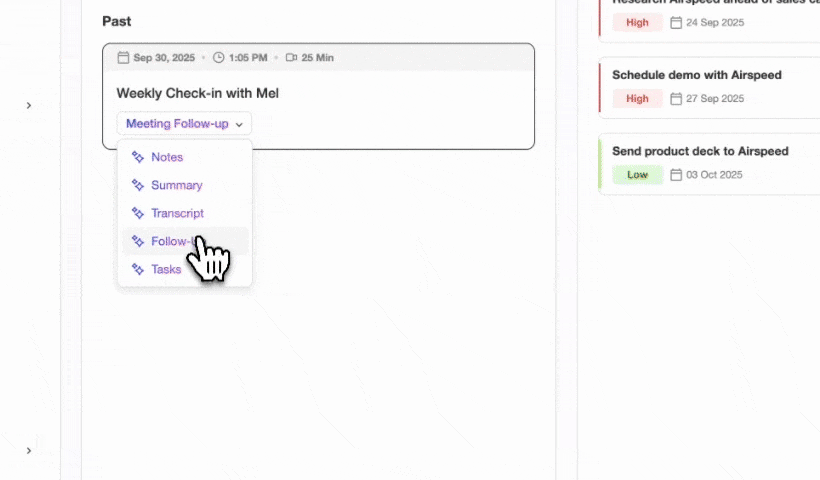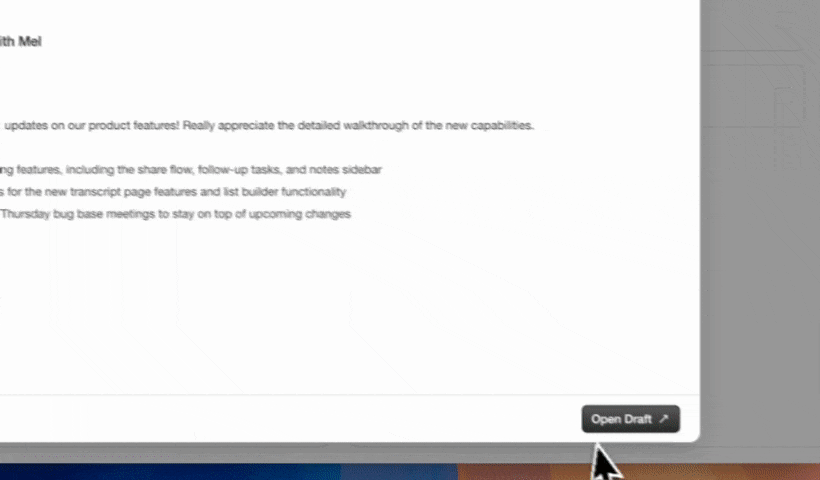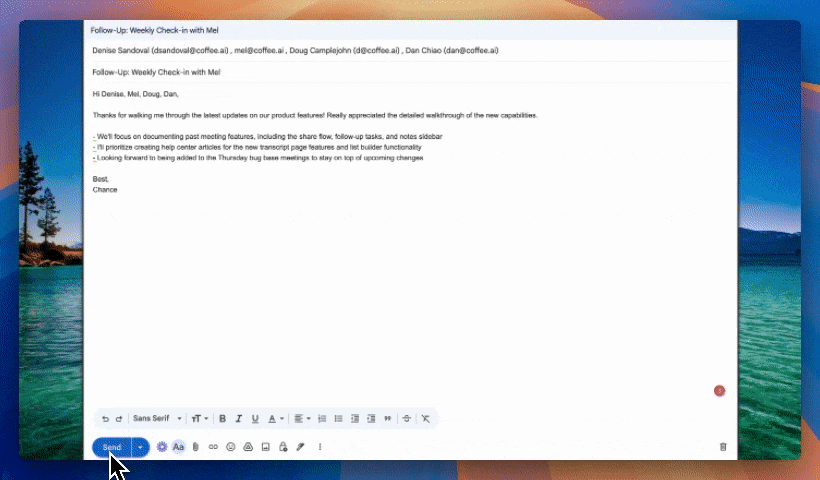
Week-Over-Week Pipeline Comparison Views
An agent that captures history in a built-in data warehouse, rather than overwriting fields, can visualize week-over-week pipeline changes. Leaders see which deals progressed, which opportunities stalled, and which records were newly added. Pipeline reviews shift from manual interrogation sessions to focused, data-driven discussions.
Predictive Win Probability You Can Trust
AI-powered forecasting tools can improve accuracy in predicting deal outcomes by analyzing behavioral signals instead of relying only on salesperson judgment and stage-based probability assignments. Clean, continuously updated data is the prerequisite for that accuracy gap to appear in real forecasts.
Implementation Paths for Agent-Led Scoring
Teams can deploy an AI CRM agent through two primary paths. One path uses a standalone CRM that replaces legacy systems entirely. The other path uses a companion layer that writes enriched, structured data back into an existing Salesforce or HubSpot instance. Both paths address the same root problem of incomplete CRM data, but each one fits a different organizational context.
| Approach | Primary Data Sources | Scoring Data Quality | Pipeline Visibility Output |
|---|---|---|---|
| Legacy CRM (manual entry) | Rep-entered fields, periodic imports | Less than half of CRM data meets accuracy standards (see data quality comparison above) | Static snapshots, stale between updates |
| Modern CRM (UI improvements, no agent) | Rep-entered fields with better UX | Improved adoption but the same structural entry limitations | Cleaner views that still depend on human discipline |
| Agent-led (standalone or companion) | Email, calendar, transcripts, enrichment APIs | High accuracy (95%+, as shown in the comparison above) | Live, continuously updated deal scores and pipeline views |
Evaluation Framework for Small-to-Mid-Market Teams
Four criteria help small-to-mid-market sales organizations decide whether an agent-led scoring solution fits their needs.
Integration effort. Platform selection criteria for AI CRM automation include integration options with existing tools, ease of use via no-code interfaces, and scalability factors such as data limits and user capacity. A companion deployment over Salesforce or HubSpot should require simple authentication instead of a multi-month implementation.
Data quality guarantees. Strict schema validation and data contracts are required in autonomous data systems to prevent bad data from polluting the decision engine. Teams should confirm that the agent enforces field validation and deduplication automatically.
Security and compliance. SOC 2 Type 2 certification and GDPR compliance form the baseline. Buyers should verify that customer data does not train shared models.
Fit for team size and workflow. According to Gartner, 65% of B2B sales organizations will shift from intuition-based to data-driven decision making by the end of 2026. For small-to-mid-market teams without dedicated data engineering resources, that shift is realistic only if the solution automates data capture and scoring without ongoing technical maintenance.
See how Coffee’s agent-led data capture fits your existing stack by reviewing the available plans and deployment options.
Frequently Asked Questions
What is deal scoring pipeline visibility?
Deal scoring pipeline visibility is the ability to view every open sales opportunity ranked by a real-time, data-driven score that reflects its likelihood of closing. It combines accurate deal scores, calculated from activity, engagement, firmographic fit, and risk signals, with a live pipeline view that updates continuously as new interactions occur. Teams no longer rely on periodic manual CRM updates.
Why do deal scores become unreliable with manual CRM entry?
Manual entry introduces errors, delays, and omissions at every stage of the data capture process. Reps who log calls from memory create incomplete records. Fields left blank remove critical scoring inputs. Formatting inconsistencies prevent reliable deduplication. As pipeline volume grows, these issues compound, and scores begin to mirror the quality of human discipline instead of actual deal health.
Can an AI agent work alongside an existing Salesforce or HubSpot instance?
Yes. A companion deployment model lets an AI agent connect to an existing Salesforce or HubSpot instance through authentication. The agent captures activity data from email and calendar automatically, enriches records with firmographic and technographic data, and writes structured, validated information back to the CRM. The system of record stays the same while the agent manages data capture so that scoring and pipeline views reflect current deal state without rep data entry.
What data sources does an AI CRM agent use to calculate deal scores?
An AI CRM agent ingests data from email threads, calendar events, call recordings and transcripts, website visitor behavior, and third-party enrichment sources covering job titles, company funding, LinkedIn profiles, and technology stack. It converts this unstructured and semi-structured data into validated CRM fields. Those fields then feed the scoring model with activity velocity, engagement depth, stage progression, historical win patterns, and risk signals.
How quickly can agent-led data capture improve forecast accuracy?
Organizations that fix CRM data quality at the source usually see measurable forecast accuracy improvements within the first 30 days. The improvement tracks directly with data completeness. As the agent fills gaps in activity logs, contact records, and deal stage history, the scoring model operates on a more complete and accurate dataset, which reduces the variance between forecast and actual revenue outcomes.
Conclusion
Inaccurate deal scores and poor pipeline visibility stem from data quality problems, not model problems. Manual CRM entry produces incomplete, inconsistent, and stale records that cause forecasts to miss and pipeline reviews to stall. An AI agent that autonomously captures activity from email, calendar, and call transcripts, enriches records with firmographic data, and writes validated, structured information back to the CRM creates a reliable foundation for real-time deal scoring and live pipeline visibility. Whether deployed as a standalone CRM for growing teams or as a companion layer over Salesforce or HubSpot, agent-led data capture removes the human bottleneck that legacy systems have never been able to solve.
Give your pipeline the data foundation it needs and review Coffee’s pricing and plans to see how agent-led capture can support accurate scoring.