
Written by: Doug Camplejohn, CEO & Co-Founder, Coffee
Key Takeaways
- Granola captures clear meeting notes, but it does not update CRM records, deal stages, or health scores on its own.
- Manual note-to-CRM workflows cause more than 90% of sales conversation intelligence to disappear and weaken forecast accuracy.
- Coffee’s autonomous agent ingests Granola transcripts, auto-creates and enriches contacts and companies, and writes BANT, MEDDIC, or SPICED fields.
- Pipeline Compare and website visitor identification give teams week-over-week visibility and route inbound leads into one unified pipeline view.
- Teams reclaim 8–12 hours per rep per week and improve forecast accuracy when they get started with Coffee.
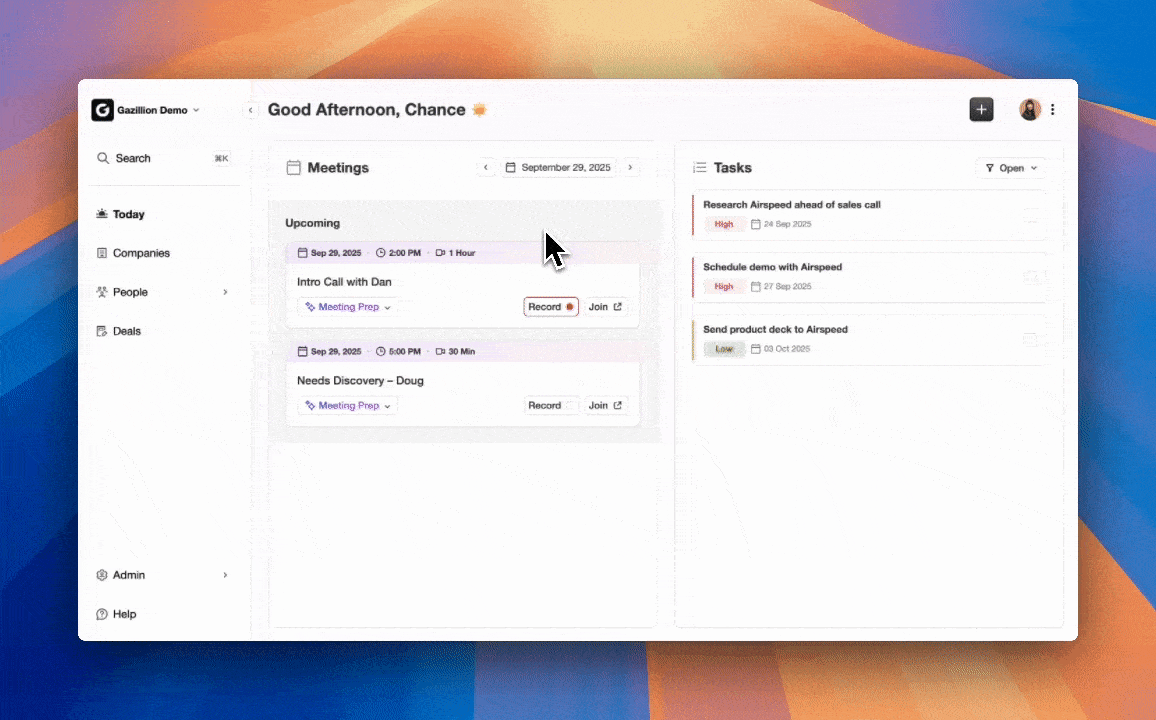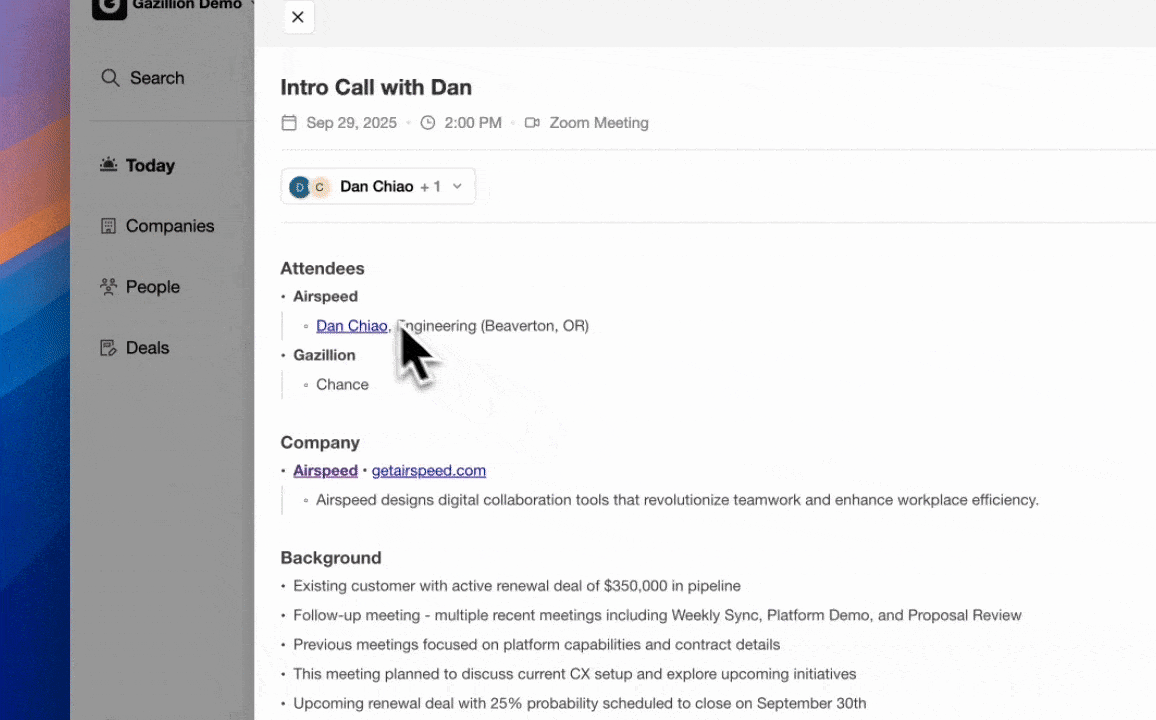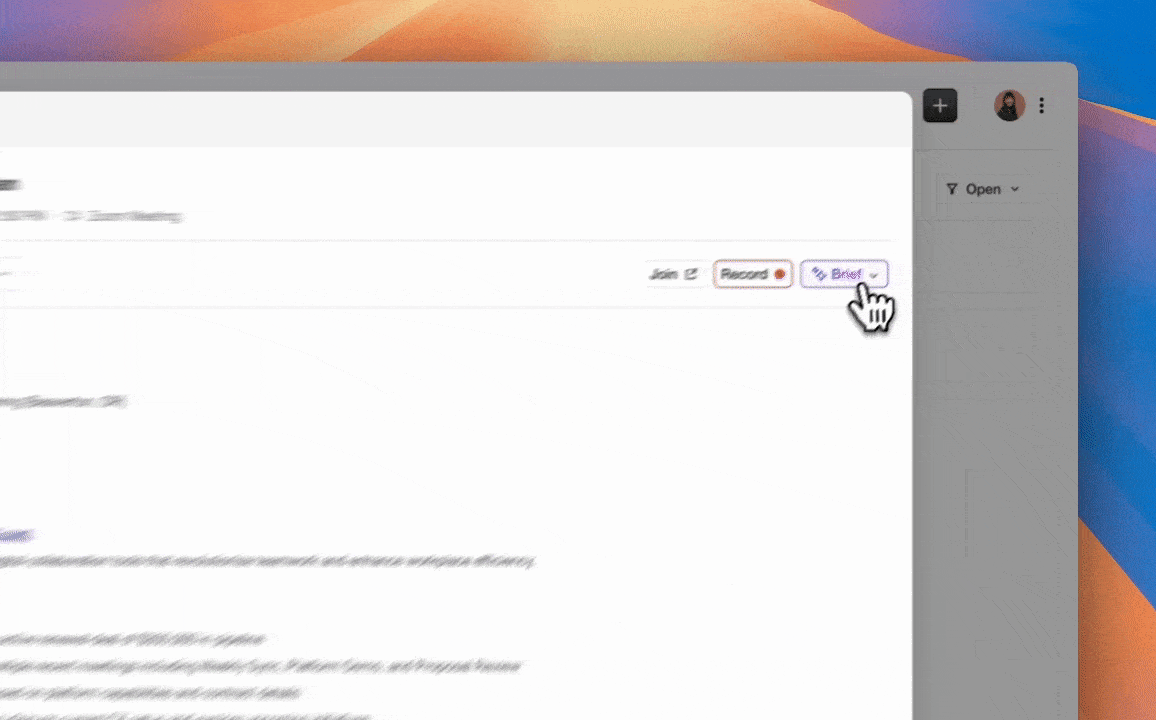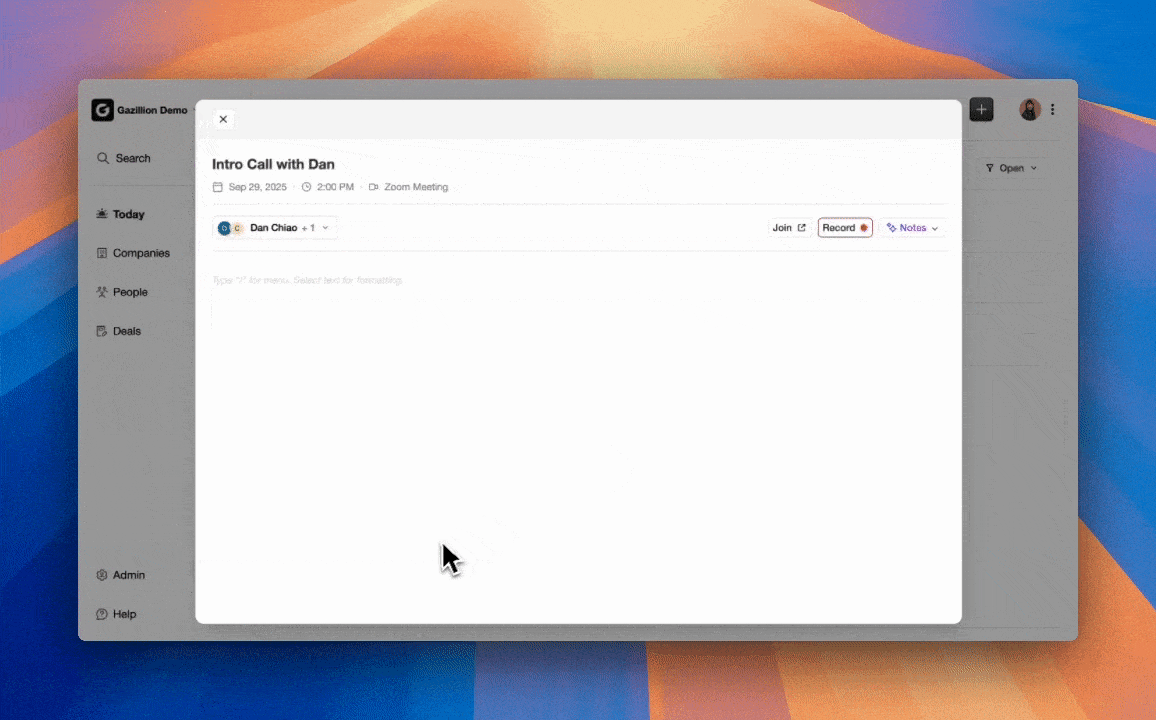
The Operational Challenge: Granola Notes Alone Leave Forecasting Gaps
Granola produces clean, readable meeting notes, but it does not create CRM records, update deal stages, or assign health scores. That work falls on reps, and they rarely complete it consistently. Sales reps spend only 35% of their work week actually selling due to manual tasks. When note-to-CRM sync stays manual, forecast inputs degrade quickly. Most B2B SaaS organizations let 90%+ of go-to-market intelligence from sales conversations evaporate because it is not systematically captured into CRM infrastructure. The result is a pipeline view based on what reps remembered to log, not what actually happened in calls.
Why Granola with Disconnected Tools Usually Fails
Integration complexity with existing enterprise ecosystems is a key challenge tempering adoption of AI note-taking tools, and Granola follows this pattern. Common failure modes include transcripts that never reach the CRM because the export step was skipped, duplicate contacts created when a rep manually adds a record that already exists, and stalled deals that show no activity because the post-call summary lived only in Granola. 95% of IT leaders cite integration as a primary AI adoption barrier. Without an agent layer enforcing the handoff, the Granola-to-CRM connection breaks at the human step almost every time.
Granola + Coffee Setup Checklist
- Active Granola account with meeting recording enabled
- Google Workspace or Microsoft 365 connected to your calendar
- Coffee account, either Standalone CRM or Companion App on Salesforce or HubSpot
- Admin access to your CRM org for Companion deployments
- Defined sales methodology: BANT, MEDDIC, or SPICED
Create your Coffee account and connect your stack before moving to Step 1.
Step 1: Connect Granola to Coffee for Automatic Transcript Flow
Inputs: Granola transcript export, Coffee API credentials. Owner: RevOps or the individual rep. Fields touched: Meeting title, attendees, date, raw transcript body.
In Coffee settings, go to Integrations and authenticate your Granola workspace. Coffee requests read access to completed meeting notes. After authorization, every Granola session triggers an automatic transcript push into Coffee’s data warehouse. Agentic AI systems integrate with other software to complete tasks independently, going beyond chatbots by perceiving, reasoning, and acting on their own. Coffee’s agent starts processing each transcript as soon as it arrives, with no manual trigger.
Troubleshooting: If transcripts do not appear in Coffee within five minutes of a call ending, confirm that Granola calendar permissions use the same Google or Microsoft account authenticated in Coffee. Mismatched accounts cause most permission failures.
Expected output: Every completed Granola meeting appears in Coffee’s activity feed, timestamped and linked to the correct calendar event.
Step 2: Let the Coffee Agent Create and Enrich CRM Records
Inputs: Parsed transcript, attendee email addresses. Owner: Coffee agent, fully autonomous. Fields touched: Contact name, title, company, email, last activity date, next activity date, associated deal.
Coffee’s agent scans each transcript for attendee identities and cross-references them against existing CRM records. New contacts and companies are created automatically, and existing records are enriched with updated titles, LinkedIn profiles, and funding data from Coffee’s licensed data partners. Duplicate prevention runs at the email-address level before any write occurs. The shift from raw transcription to contextual understanding in AI note-taking tools is especially valuable for sales cycle analysis and deal-history analysis through CRM integration. Coffee’s agent handles this enrichment loop without rep involvement, removing the manual data-entry burden that usually consumes most non-selling time.

Expected output: Clean, enriched contact and company records with activity logs current to the minute of the last call.

Step 3: Configure Meeting Briefings and Post-Call Summaries with BANT, MEDDIC, or SPICED
Inputs: Transcript and selected sales methodology. Owner: RevOps for configuration, Coffee agent for execution. Fields touched: Qualification fields mapped to the chosen framework, next steps, action items, follow-up draft.
In Coffee Meeting Settings, select the methodology that matches your sales motion. BANT maps Budget, Authority, Need, and Timeline to discrete CRM fields. MEDDIC adds Metrics, Economic Buyer, Decision Criteria, Decision Process, Identify Pain, and Champion. SPICED covers Situation, Pain, Impact, Critical Event, and Decision. Post-meeting AI capabilities that auto-generate summaries and update CRM fields directly convert unstructured meeting outcomes into structured pipeline data. Coffee’s agent extracts the relevant signals from each Granola transcript, writes them into the corresponding CRM fields, and drafts a follow-up email for rep review in Gmail.
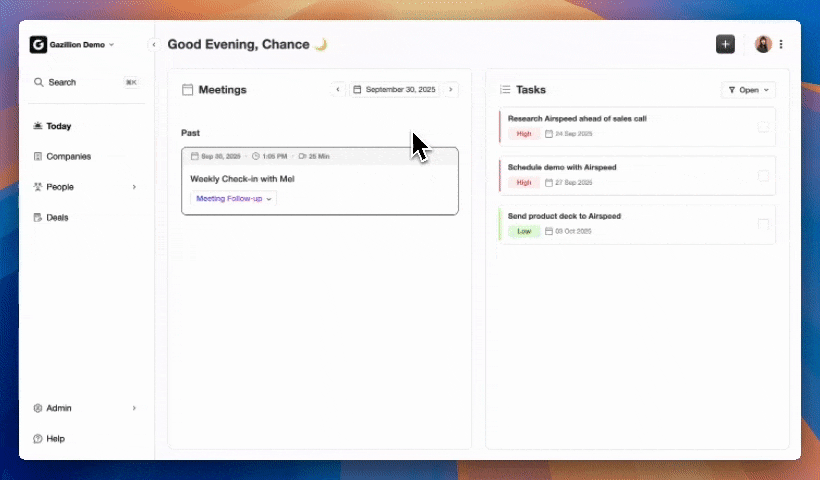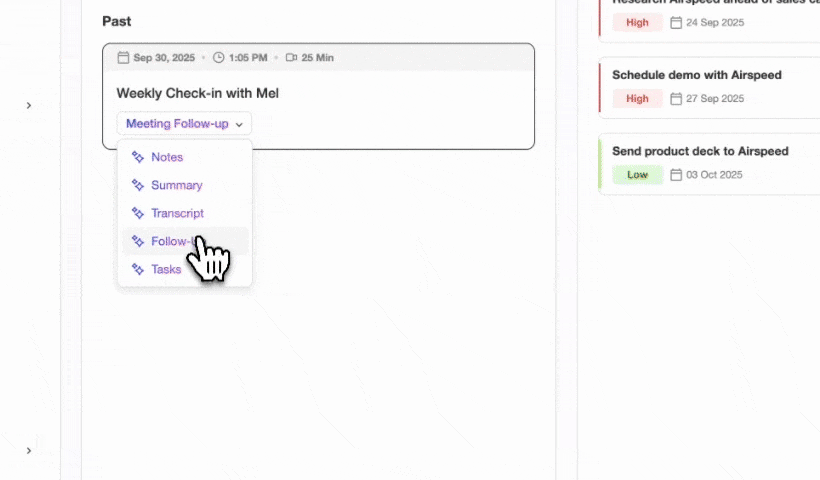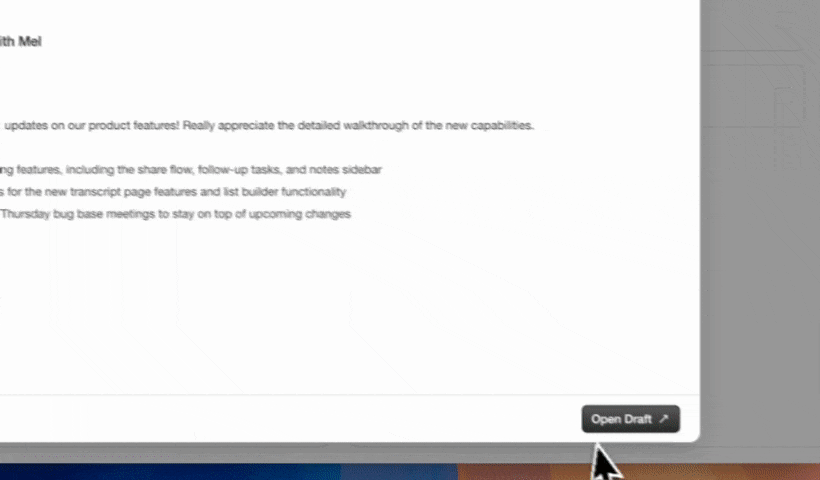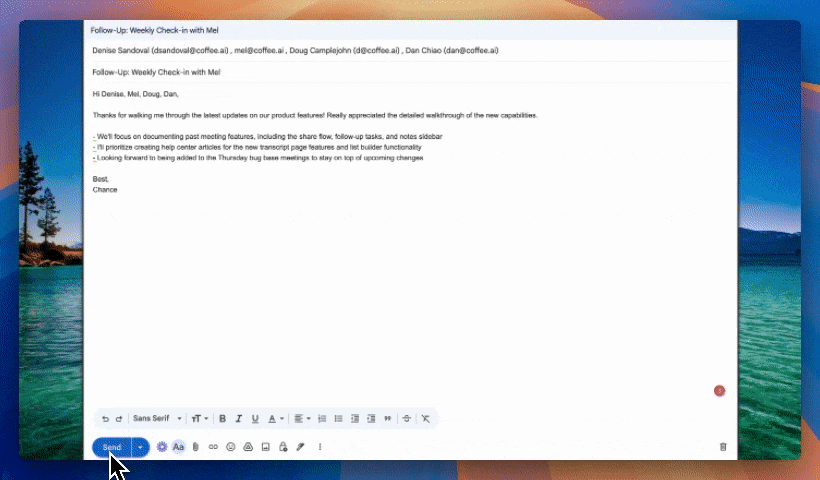
Expected output: Structured qualification data in CRM fields, action items assigned to owners, and a draft follow-up ready to send.
Step 4: Turn On Pipeline Compare for Week-over-Week Visibility
Inputs: Historical deal snapshots stored in Coffee’s data warehouse. Owner: Coffee agent. Fields touched: Deal stage, close date, deal value, last activity, health score.
In the Coffee Pipeline view, enable the Compare toggle. Select the baseline week and the current week. Coffee’s agent renders a side-by-side view that surfaces three deal categories: progressed, stalled, and new. Progressed deals show a stage advance or a pulled-in close date. Stalled deals show no activity within a configurable window. New deals appear if they were created after the baseline. Static approaches cause intelligence to evaporate between meetings and misalignment to be discovered only retrospectively in quarterly reviews. Pipeline Compare replaces that retrospective discovery with a live, annotatable view that you can screenshot and share during weekly pipeline calls.
Expected output: A visual, week-over-week pipeline diff that replaces manual CSV exports and spreadsheet comparisons.
Step 5: Install Visitor Identification to Feed the Same Pipeline View
Inputs: Coffee-generated tracking script. Owner: Web developer or marketing ops. Fields touched: Visitor name, title, email, company, pages visited, visit frequency.
Copy the pixel script from Coffee Visitor ID settings and paste it into the <head> tag of your website. Coffee verifies installation automatically. From that point, anonymous website traffic resolves to named individuals with name, title, email, and LinkedIn profile, along with behavioral data such as pages visited and time on site. Real-time Slack notifications surface high-fit visitors. Coffee’s Suggested Leads feature then recommends two or three specific contacts inside each visiting company who match your buyer persona, ready for LinkedIn outreach or outbound sequences. These identified leads route directly into the same Coffee pipeline view that Granola transcripts populate, which creates a unified demand signal across inbound and outbound.
Expected output: Named, enriched leads from website traffic appearing alongside meeting-sourced deals in a single pipeline view.
Validation: Data-Quality Checks, Forecast Accuracy, and Time Saved
Once all five steps are live, the workflow needs validation to confirm it delivers the promised time savings and forecast improvements. After two weeks of running the full workflow, audit three metrics that together confirm the agent is closing the Granola-to-CRM gap. Start with CRM field completion rate. Qualification fields for BANT, MEDDIC, or SPICED should be populated on more than 90% of active opportunities without rep input, which proves the agent is extracting and writing structured data reliably. Next, measure forecast variance by comparing your rolling four-week forecast accuracy before and after Coffee deployment. Forecast accuracy gains depend heavily on CRM hygiene; when activity logging is automated, model inputs become reliable. Finally, quantify rep time reclaimed. Coffee targets 8–12 hours per rep per week recovered from manual data entry, which you can validate through rep surveys or time-tracking data. Automated conversation intelligence cuts call-review time by up to 80%.
If field completion sits below 90%, confirm that Granola transcript export format has not changed, because Coffee’s parser requires the standard Granola JSON output. If forecast variance has not improved, verify that deal stages map correctly between Coffee and your Salesforce or HubSpot pipeline stages.
Run this validation against your own pipeline by connecting Coffee to your CRM.
Scaling the Workflow Across Standalone, Companion, and MCP
Smaller teams can keep Coffee as the full system of record, while larger teams can run Coffee as a Companion App on top of an existing CRM. For teams of one to five reps, Coffee Standalone handles the entire system of record. Granola transcripts flow in, and Coffee’s agent manages contacts, deals, and Pipeline Compare without any external CRM dependency. Setup stays quick and lightweight.
For teams of 20–50 reps already on HubSpot or Salesforce, Coffee deploys as a Companion App. The agent writes enriched data back to the primary CRM and preserves existing workflows, quota structures, and required fields. For advanced forecasting, Coffee supports Model Context Protocol, or MCP, the Anthropic-introduced standard that eliminates custom integration code by standardizing how agents connect to external tools and data sources. Teams running Claude via MCP can query Coffee’s data warehouse in natural language, receive structured outputs, and avoid building custom reports.
Granola + Coffee vs Granola + Sybill: Capability Comparison
The table below highlights six capabilities that distinguish Coffee’s agent-driven workflow from Sybill’s call-intelligence focus, so you can evaluate which stack supports a complete Granola-to-pipeline process.
| Capability | Granola + Coffee | Granola + Sybill | Notes |
|---|---|---|---|
| Automatic CRM record creation | Yes, contacts, companies, and activities auto-created | Yes, Sybill creates CRM fields from call data | Both automate creation, and Coffee also enriches with firmographic data via licensed partners |
| Week-over-week pipeline compare | Yes, native Pipeline Compare feature with deal-level diff | No native pipeline compare, requires CRM reporting layer | Coffee Compare runs on an internal data warehouse. Pipeline visibility without a data warehouse loses historical context |
| Sales methodology structuring (BANT/MEDDIC/SPICED) | Yes, configurable per team | Yes, Sybill supports MEDDIC and custom frameworks | Like-for-like capability, and Coffee writes outputs to Salesforce or HubSpot fields or Standalone CRM |
| Website visitor identification | Yes, pixel-based, named individual plus Suggested Leads | No | Coffee closes the inbound-to-pipeline loop, while Sybill focuses on call intelligence only |
| Standalone CRM option | Yes, full system of record for teams not on Salesforce or HubSpot | No, requires existing CRM | Relevant for sub-20-rep teams evaluating their first CRM |
| MCP / Claude integration | Yes | Not publicly documented as of June 2026 | MCP standardizes agent-to-CRM connections without custom code |
Start a Coffee trial and see how the full agent workflow performs in your own environment.
Frequently Asked Questions
How long does it take to set up the Granola + Coffee workflow?
Teams can set up the Granola + Coffee workflow quickly, with different timelines for Standalone and Companion deployments. For Coffee Standalone, the full workflow of Granola integration, contact auto-creation, methodology configuration, and Pipeline Compare comes together in a short session. For the Companion App on HubSpot or Salesforce, setup requires authenticating Coffee against your existing CRM org and mapping deal stages. Both deployment paths avoid custom code.
Is Coffee SOC 2 Type 2 and GDPR compliant?
Coffee is SOC 2 Type 2 certified and GDPR compliant. Meeting transcripts and CRM data processed by the Coffee agent are not used to train public AI models. Teams in regulated industries or those handling sensitive customer data can request Coffee security documentation through the pricing page.
How does Coffee’s pricing work for this workflow?
Coffee uses seat-based pricing, so you pay for human seats on your team. The agent’s labor, including transcript processing, record creation, enrichment, Pipeline Compare, and visitor identification, is included without metered charges per process or per LLM call. As a result, the cost of running the full Granola-to-pipeline workflow scales with headcount, not with call volume or data throughput.
What happens to the workflow as the sales team grows?
The workflow scales across both Coffee deployment models. A five-rep team on Coffee Standalone can migrate to the Companion App when they adopt Salesforce or HubSpot, and Coffee continues to handle the data-in layer while the existing CRM remains the system of record. For teams growing to 30 or more reps, the MCP integration with Claude enables natural-language querying of Coffee’s data warehouse, which supports more sophisticated forecasting and pipeline analysis without rebuilding the underlying workflow.
What if Granola changes its export format or API?
Coffee maintains the integration layer on its side, so customers avoid ongoing maintenance. If Granola updates its transcript format, Coffee pushes a parser update without requiring customer action. The recommended validation step, checking that transcripts appear in Coffee’s activity feed within five minutes of call completion, serves as the practical health check for the integration. If transcripts stop appearing, the Coffee support team can diagnose whether the issue is a format change, a permission lapse, or a calendar account mismatch.


