Written by: Doug Camplejohn, CEO & Co-Founder, Coffee
Key Takeaways for Revenue‑Unified Enablement
- Revenue-unified enablement depends on CRM records, content, and pipeline KPIs sharing one continuously synchronized data layer. Without that shared layer, every downstream tool runs on stale or incomplete data.
- Poor CRM data quality is the primary reason enablement investments fail to deliver ROI. Only about half of leaders can show results, and manual entry costs U.S. companies $28,500 per employee annually.
- Effective platforms support two-way CRM sync, automation that fixes data at capture, direct linkage of content usage to deal outcomes, and native architecture that avoids extra integration work.
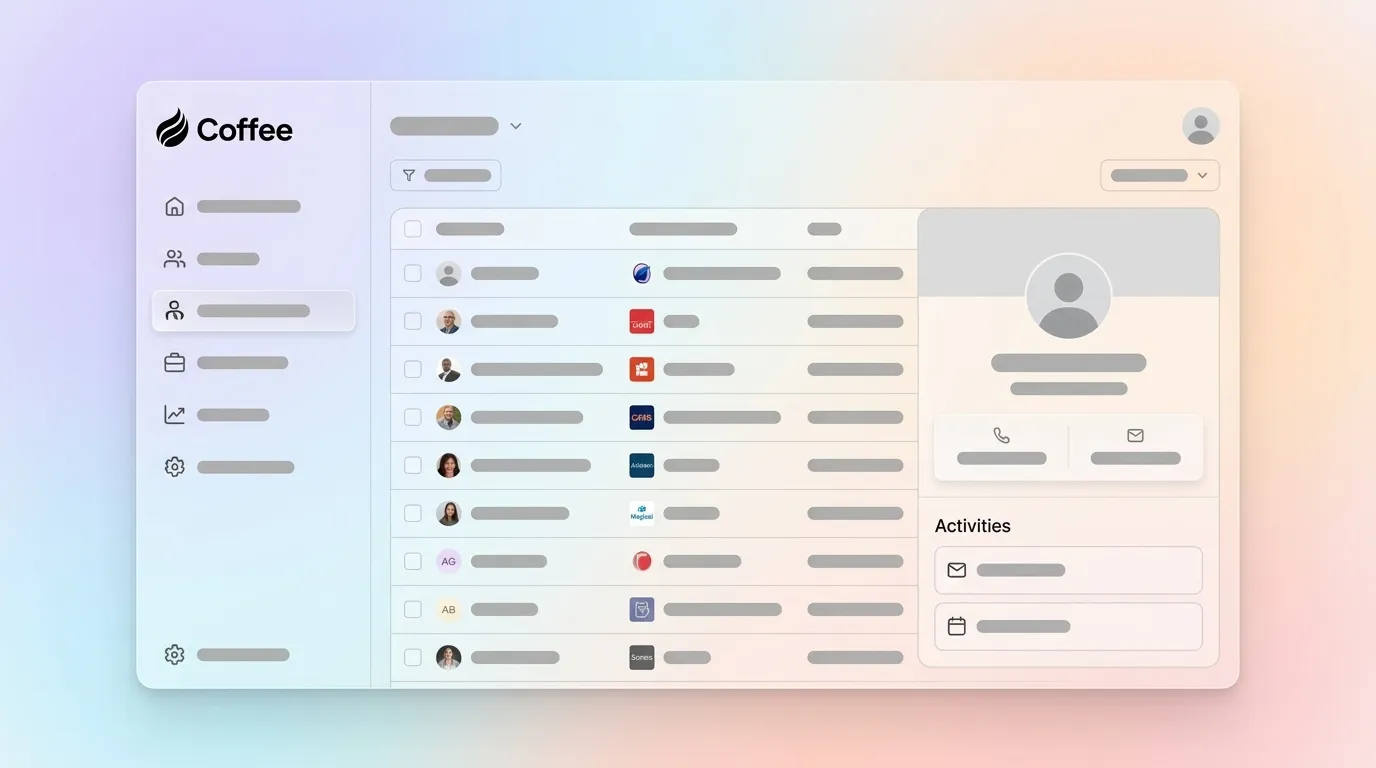
- Among evaluated platforms, Coffee stands out with real-time two-way sync, agent-driven auto-capture, and automatic revenue attribution through Stripe and QuickBooks integrations.
- Start with Coffee to eliminate dirty data at the source and unlock accurate enablement across your entire revenue stack—see pricing and deployment options.
How Poor CRM Data Kills Enablement ROI
Failed enablement investments usually stem from bad CRM data, not from the enablement platform itself. The CRM data feeding it breaks the model. Content analytics that correlate asset usage with deal velocity require clean, structured CRM data, and without that foundation, organizations cannot see which playbooks move pipeline or justify enablement spend. This measurement gap, where fewer than half of enablement leaders can prove ROI to executives, comes directly from weak data quality and inconsistent CRM records.
The manual entry burden makes the problem worse. The financial impact averages nearly $30,000 per employee each year in lost productivity and error correction, and dirty data often stalls CRM integration projects before they deliver value.
Automation and AI agents can remove repetitive administrative tasks only when they receive high-quality CRM data. Poor data quality blocks these tools from reliably qualifying leads, scheduling appointments, or supporting playbook execution tied to revenue outcomes.
Evaluation Criteria for Revenue-Unified Platforms
To solve the data-quality problem at its source, platforms must be judged on how they capture, sync, and maintain accurate CRM records. Four dimensions determine whether a platform delivers true revenue-unified enablement or simply adds another disconnected layer to the stack.
Sync Direction. A one-way sync from an ERP or accounting system to the CRM presents a different technical challenge than a bidirectional integration, making directionality a primary evaluation criterion when assessing integration depth. This matters because platforms that only push data out cannot receive updated deal context back from the CRM, so changes to stages, contacts, or pipeline status stay invisible to the enablement layer.
Data-Quality Automation. Two-way sync with the CRM is non-negotiable for modern sales enablement platforms, and the platform should surface content recommendations inside Salesforce, HubSpot, or Microsoft Dynamics rather than forcing sellers into a separate workflow. Automation that fixes records at the point of capture, not weeks later, becomes the real differentiator.
Revenue KPI Linkage. Stronger platforms connect content usage and training completion to deal outcomes in the CRM instead of only tracking activity counts. This connection enables revenue attribution, such as identifying content combinations that consistently drive higher win rates.
Native vs. Layered Architecture. Native-platform architectures combine the AI agent and the underlying system of record in one product, which removes handoff friction and creates a single feedback loop for reporting and improvement. Agent-specialist tools that sit on top of existing systems require separate integrations, which increases implementation complexity and total cost of ownership.
Platform Comparison: Integration Scorecard
The table below scores six platform categories across the four evaluation dimensions. Every rating reflects published integration capabilities as of mid-2026.
| Platform | Sync Direction | Data-Quality Automation | Revenue KPI Linkage |
|---|---|---|---|
| HubSpot Sales Hub | Bidirectional within HubSpot ecosystem, limited cross-platform | Manual field mapping, relies on rep entry for deal stage accuracy | Native reporting, attribution breaks when data is incomplete |
| Salesforce + Highspot / Seismic | Bidirectional with Salesforce, enablement layer requires separate configuration | Enrichment via third-party add-ons (e.g., ZoomInfo), no native auto-capture | Content-to-deal attribution available but dependent on clean underlying CRM data |
| Mindtickle | Bidirectional with Salesforce, HubSpot, Dynamics | Readiness scores mapped to CRM, Call AI connects call performance to Readiness Index and CRM win rates | Correlates seller skills directly to CRM win rates and deal sizes |
| Seismic (standalone) | One-way content push, CRM write-back limited | No native data-entry automation, depends on CRM hygiene upstream | Content engagement analytics, pipeline linkage requires CRM integration depth |
| Gong / Clari (intelligence layer) | Reads from CRM, selective write-back of call insights | Auto-logs call activity, some tools auto-fill CRM fields and generate follow-up emails post-call | Strong pipeline forecasting, dependent on complete CRM records for accuracy |
| Coffee (Standalone CRM or Companion App) | Bidirectional, summary templates write back to Coffee, HubSpot, or Salesforce, Stripe and QuickBooks sync revenue data in real time | Agent auto-creates contacts, logs activity, and enriches records from email and calendar without rep input | Pipeline Compare tracks week-over-week changes, Stripe integration marks Closed Won automatically from payment events |
Deploy Coffee’s agent layer to keep every row in this table accurate, and see how two-way sync and auto-capture behave in your CRM.
Category-by-Category Analysis of Platform Fit
Setup Effort. Salesforce-plus-enablement stacks carry the highest configuration burden. A 180-day implementation roadmap for mid-market enablement imposes ongoing operational overhead: Phase 1 requires CRM audits and gap analysis, Phase 2 demands standardization of deal stages and centralized repositories, and Phase 3 requires training, rollout, and continuous KPI monitoring. Coffee’s Companion App deploys through a single authentication step against an existing Salesforce or HubSpot instance, which shortens time-to-value significantly.
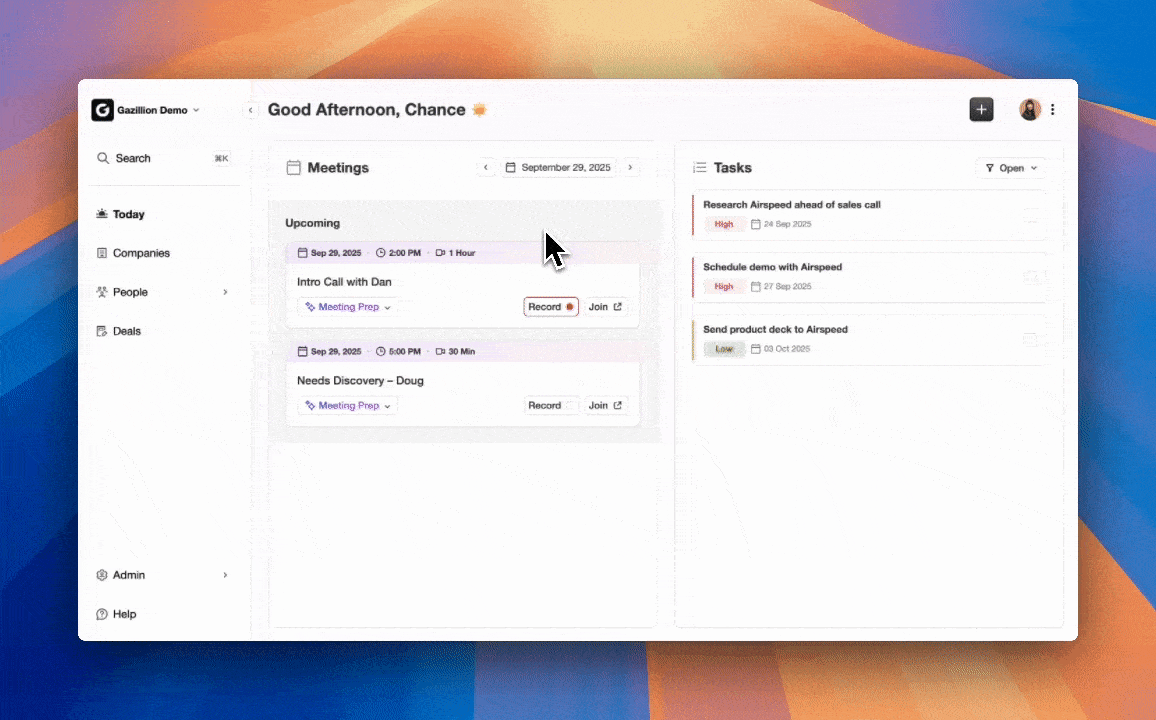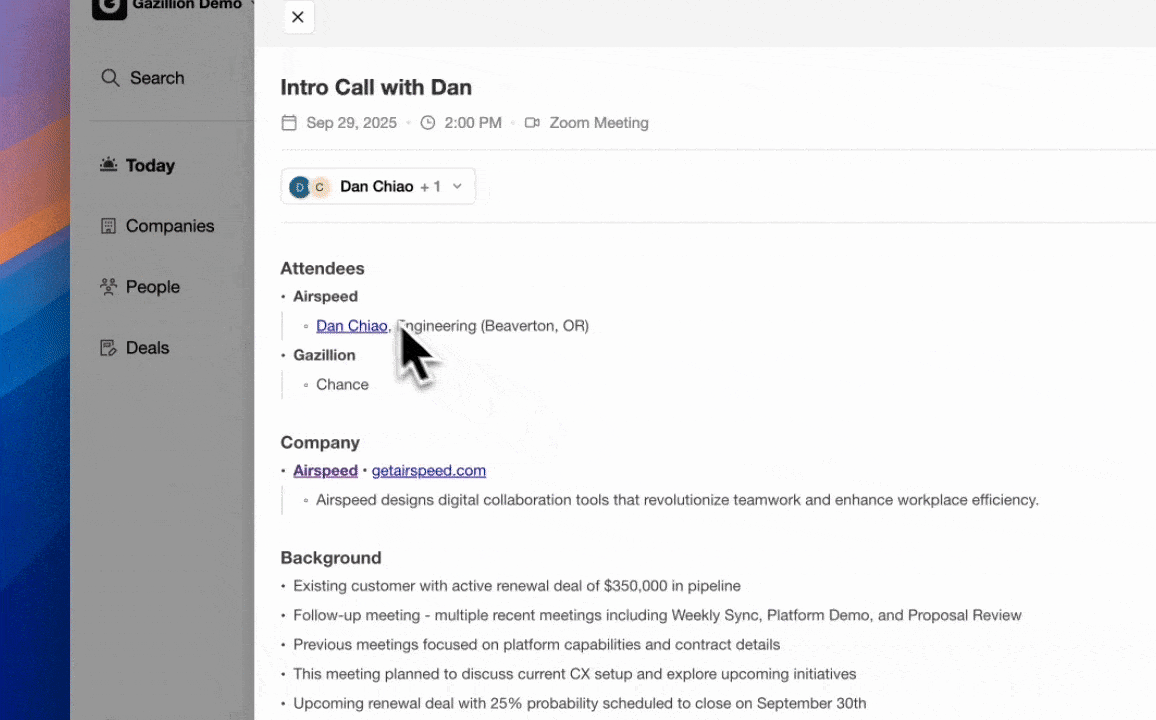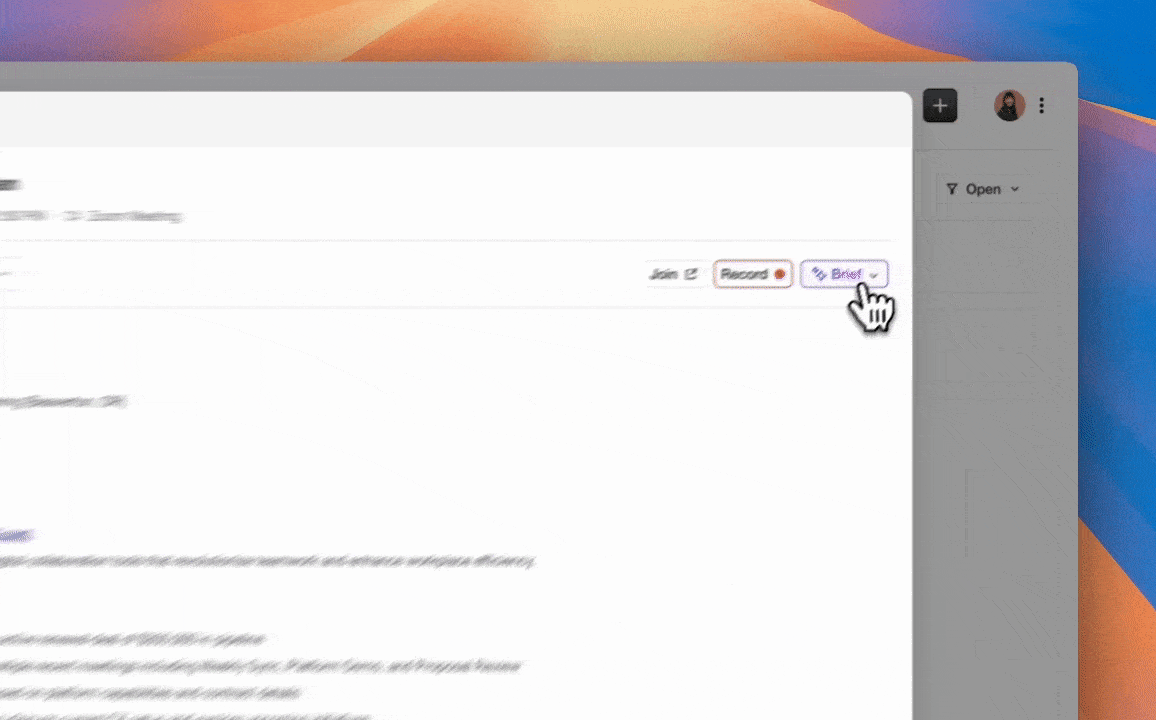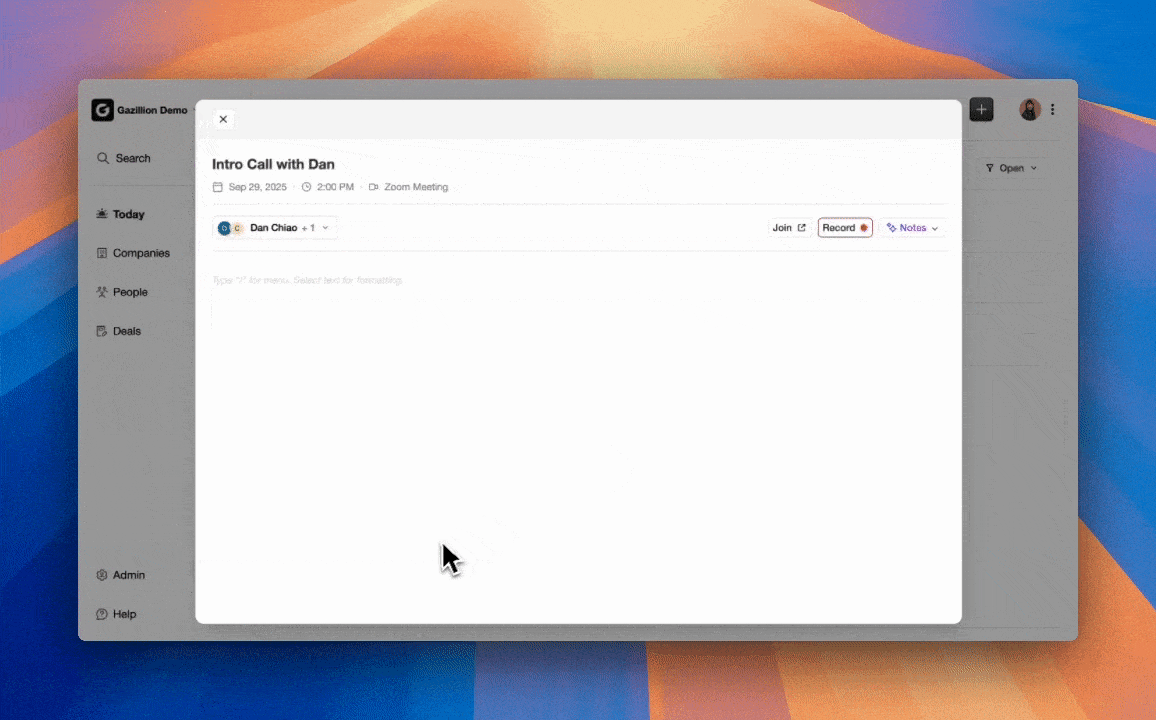
Data Capture Automation. Sales automation software auto-logs CRM activity to save reps hours each week on manual input, keep data clean for accurate forecasting, and reduce admin drag during busy deal cycles. Coffee’s agent captures emails, calendar events, and call transcripts at the source, so it removes the entry step entirely instead of cleaning up errors later.
Frontline Usability. Integration depth should be evaluated by whether the platform works natively inside the CRM or forces users to switch tabs, with the strongest platforms delivering contextual recommendations based on deal stage, buyer persona, and account history pulled directly from the CRM. Platforms that require constant tab-switching see lower adoption and worse data quality downstream.
Manager Visibility. Enablement success is measured through sales cycle length, onboarding time, win rate, content usage, and time spent selling, which requires reliable CRM data and consistent KPI definitions across pipeline records. Coffee’s Pipeline Compare feature surfaces week-over-week deal movement automatically and replaces manual CSV exports in pipeline reviews.
Long-Term Scalability. In 2026, market leaders will be the organizations with the best-integrated ecosystem of automation tools rather than the companies with the most tools. Platforms that reduce stack complexity while maintaining strong data-quality automation scale more predictably than those that expand integration surface area with every new feature.
Agent vs. Passive Database Architectures in 2026
Legacy CRMs such as Salesforce, HubSpot, and Dynamics are relational databases built on the assumption that humans will reliably enter structured data into defined fields. That assumption has never held. Seventy-one percent of enterprise apps remain isolated, which highlights the need for automation platforms with seamless CRM and ERP integrations so data can move freely.
Agent-layer architectures invert this model. The agent captures the transcript instead of waiting for a rep to log a call, extracts structured fields, and writes them back to the system of record automatically. This automatic capture enables Coffee’s Intelligence layer, introduced in February 2026, to go beyond simple field population. It allows users to define and store deep context on business model, product specifics, ICP, and competitors, then use that context to generate tailored AI suggestions and insights. Passive databases cannot match this capability because they lack the unstructured-data processing layer required to extract meaning from calls and emails.
Advanced AI agents in B2B sales platforms update CRM records, score leads, recommend next best actions, and generate revenue forecasts, with effectiveness dependent on reliable underlying CRM data linkage. The agent architecture addresses the data-quality problem at the source instead of treating it as a manual governance issue.
Best-Fit Use-Case Scenarios for Coffee
Early-stage teams (1–20 reps). Coffee’s Standalone CRM fits these teams well. Groups that have outgrown spreadsheets but view HubSpot or Pipedrive as expensive maintenance burdens gain from an agent that handles all data entry from day one, with no legacy migration required.
Scaling mid-market organizations (20–150 reps). Coffee’s Companion App on Salesforce or HubSpot addresses low adoption and dirty data without forcing a platform migration. The Stripe integration automatically imports customers, enriches them, and marks deals as Closed Won from payment events, so payment activity closes the loop between revenue data and CRM records without manual updates.
Teams committed to Salesforce or HubSpot. Mindtickle and Highspot or Seismic add enablement content and coaching layers on top of Salesforce, but both depend on clean underlying CRM data to deliver accurate recommendations. Layering Coffee’s agent underneath these platforms as the data-quality foundation addresses the root cause instead of working around it.
Risks and Limitations to Consider
Hidden maintenance. Organizations must work with sales operations to standardize fields, ownership rules, stage definitions, and exit criteria to tighten CRM hygiene and improve reporting accuracy. This governance overhead persists regardless of the platform selected.
Incomplete automation. No platform removes every manual step. Vendors should be asked about pre-built connectors and two-way data flow before purchase. Buyers should also test live integrations with their specific CRM during evaluation instead of relying only on vendor demos.
Overbuying. Sales enablement depends on a technology stack that includes CRM systems, sales engagement tools, content management platforms, learning platforms, conversation intelligence, and a data layer, which creates integration complexity as a major operational challenge for revenue teams. Adding platforms without fixing the underlying data-quality problem increases complexity without improving outcomes.
Decision Framework and Checklist for Next Steps
Use your primary constraint to choose the right starting point and avoid unnecessary tools.
Dirty CRM data as the main constraint. Deploy Coffee’s Companion App before adding any new enablement layer. Clean data becomes the prerequisite for every other platform on this list to function correctly.
Content-to-revenue attribution as the main constraint. Evaluate Mindtickle or Highspot on top of a clean CRM. Confirm two-way data flow with your specific CRM instance before signing.
Pipeline visibility as the main constraint. Coffee’s Pipeline Compare and Stripe or QuickBooks integrations provide week-over-week deal tracking and real-time revenue data without extra BI tooling.
Rep adoption as the main constraint. Sales team participation and adoption of the CRM is critical because the system can only operationalize what it is given, and leadership must enforce consistent data entry or the enablement-to-pipeline linkage fails. An agent that removes the entry burden offers a structural fix, while governance policies alone do not.
Test Coffee against your CRM and see how the agent layer captures and cleans data in real time.
Frequently Asked Questions
How long does it take to implement Coffee alongside an existing Salesforce or HubSpot instance?
Coffee’s Companion App connects to Salesforce or HubSpot through a single authentication step. After authentication, the Coffee Agent begins scanning emails and calendar events to auto-create contacts, log activities, and enrich records. Most teams see the agent actively populating and cleaning CRM data within the same business day. There is no multi-phase implementation roadmap, no field-mapping workshop, and no professional services engagement required for standard deployments.
What happens to historical CRM data during a migration to Coffee’s Standalone CRM?
For teams moving from spreadsheets or a legacy CRM to Coffee’s Standalone product, the agent ingests existing contact and company records during onboarding. Because Coffee uses a data warehouse architecture instead of a flat relational database, historical context stays preserved rather than overwritten when records change. Teams that have been operating in Notion or Google Sheets often find that the agent fills in missing fields automatically from connected email and calendar history, which reduces the manual cleanup work that usually comes with a CRM migration.

How does Coffee handle data security and compliance?
Coffee is SOC 2 Type 2 certified and GDPR compliant. Data ingested by the Coffee Agent, including email content, calendar events, and call transcripts, is not used to train public AI models. For teams in regulated industries, Coffee recommends confirming that their specific compliance requirements fall within these certifications before deployment, because highly regulated sectors such as healthcare and finance may require additional review cycles that extend beyond Coffee’s standard onboarding timeline.
How does Coffee’s data enrichment quality compare to dedicated enrichment tools like ZoomInfo or Apollo?
Coffee’s agent enriches contact and company records with job titles, funding data, and LinkedIn profiles through licensed data partners, which provides coverage roughly on par with standalone enrichment tools for most mid-market use cases. The main difference is consolidation. Coffee performs enrichment, activity logging, meeting recording, and pipeline tracking within a single agent, so teams avoid maintaining and integrating separate point solutions. Teams with highly specialized enrichment requirements, such as technographic data at enterprise scale, may still benefit from a dedicated enrichment layer connected to Coffee via Zapier.
Can Coffee link enablement activity directly to pipeline KPIs?
Coffee can link enablement activity directly to pipeline KPIs. Because the Coffee Agent captures interactions at the source and writes them back to the system of record in real time, pipeline KPIs reflect actual deal activity instead of rough manual estimates. The Pipeline Compare feature tracks week-over-week changes automatically and surfaces progressed deals, stalled opportunities, and new additions without CSV exports or manual reporting. For teams using Coffee’s Stripe or QuickBooks integrations, payment events and invoice statuses flow directly into deal records, which creates a closed loop between revenue data and CRM pipeline without extra configuration.
Conclusion: Coffee as the Enablement Foundation
The core problem in sales enablement is not a lack of platforms. Every platform in the stack, including content management, coaching, and forecasting, depends on CRM data that manual entry has made unreliable. A revenue enablement platform helps the sales organization only when source data stays complete, recent, and governed by one operating standard every day. An AI agent that captures data at the source, writes it back in both directions, and unifies structured records with live revenue signals from Stripe and QuickBooks becomes the foundation that makes every other tool accurate.
Coffee serves as that foundation, either as a standalone AI-first CRM for growing teams or as a Companion App that brings data-quality automation to existing Salesforce and HubSpot installations. The agent handles entry, enrichment, meeting summaries, and pipeline tracking, so reps can sell and managers can see reality clearly.
Build your enablement foundation with Coffee and deploy the agent layer that keeps your entire stack accurate.


